VRRP, Anycasts, Fabrics and Optimal Forwarding
The Optimal L3 Forwarding with VARP/VRRP post generated numerous comments, ranging from technical questions about VARP (more about that in a few days) to remarks along the lines of “you can do that with X” or “vendor Y supports Z, which does the same thing.” It seems I’ve opened yet another can of worms, let’s try to tame and sort them.
FHRP Basics
First-hop redundancy protocols (FHRP) solve a simple problem: IPv4 has no standard host-to-router protocol. Hosts are usually configured with a static address of the first-hop router, forcing the routers to share an IP address (sometimes called Virtual Router IP Address) in redundant environments. In most cases the routers also share the MAC address of the shared first-hop router IP address to work around broken or misconfigured secured IP stacks that ignore gratuitous ARPs sent after the ownership of the shared IP address changes.
Typical FHRP use case is a large layer-2 domain connecting numerous end hosts to more than one router. The routers are (relatively) close together, and there’s some indeterminate layer-2 infrastructure (anything from a thick coax cable to large TRILL or SPB fabric) between the end hosts and the routers.
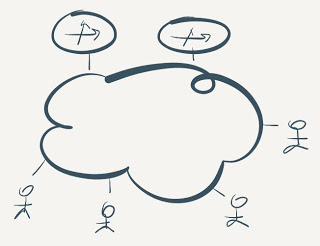
Typical FHRP use case
The first-hop routers cannot rely on any particular forwarding behavior of the underlying layer-2 infrastructure; each router must have its own set of MAC addresses that have to be active – traffic must be sourced from those MAC addresses lest the layer-2 switches start flooding the unicast traffic sent to one of the router’s MAC address.
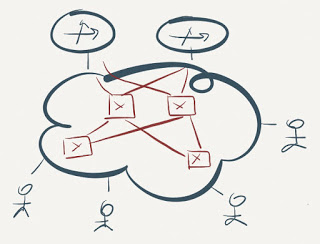
Connecting routers using FHRP to a fabric
The active MAC address requirement usually limits the number of active FHRP forwarders to one – multiple forwarders using the same MAC address would cause serious MAC flapping on intermediate switches, and the intermediate switches wouldn’t be able to perform load balancing toward multiple identical MAC addresses anyway.
Data Center Use Case
The primary goal of optimal layer-3 forwarding in a data center environment is to minimize the leaf-to-spine traffic in environments where the amount of east-west (server-to-server) traffic significantly exceeds the amount of north-south (server-to-client) traffic. The only way to reach this goal is to introduce layer-3 forwarding functionality into hypervisors or (failing that) the top-of-rack (ToR) switches.
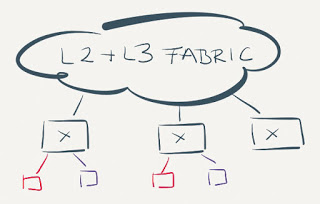
High-level view of an optimal data center fabric
The ability to migrate a running VM between physical hosts (and ToR switches) introduces additional requirements: all ToR switches have to share the same MAC address; nobody likes to see the traffic trombones that result from a VM being pinned to a MAC address of a remote ToR switch.
The Solutions
As always the networking industry tried to “solve” the problem by introducing all sorts of hacks inspired ideas, some of them more useless than the others. The most common ones (described in this blog post) are:
- No FHRP (core switches appear as a single entity);
- Active/Active FHRP on a MLAG pair;
- GLBP.
More creative solutions are described in other blog posts:
- Optimal L3 forwarding with VARP or active/active VRRP
- QFabric part 3 - forwarding (now mostly obsolete)
- Building large L3 fabrics with Brocade VDX switches (completely obsolete/EoL)
No FHRP with Single Control Plane
Vendors that implement redundant switching fabrics with a single control plane (Cisco’s VSS, HP’s IRF, Juniper Virtual Chassis) don’t need FHRP. After all, the whole cluster of boxes acts as a single logical device with a single set of IP and MAC addresses.
Before someone persuades you to solve optimal L3 forwarding problem with a virtual stack of ToR switches spread all over your data center (and I’ve seen consultants peddling this “design” to unsuspecting customers), consider how the traffic will flow.
Active/Active FHRP over MLAG
Almost every vendor offering MLAG functionality across a pair of independent core switches (Cisco’s vPC, Arista, Nokia…) supports active/active FHRP forwarding on the core switches:
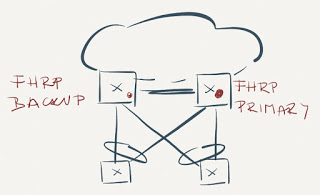
Active/Active FHRP
This solution is almost a no-brainer, although the implementation details must be pretty complex, otherwise it’s hard to understand why it took some vendors years to implement it. Here’s how it works:
- FHRP is configured on the members of the MLAG group. One of the members is elected as the active FHRP gateway and advertises the FHRP MAC address.
- All members of the MLAG group listen to the FHRP MAC address;
- Packets coming from the FHRP MAC address (example: VRRP advertisements) are sent over one of the LAG member links to the ToR switch – ToR switch thus knows how to reach the FHRP MAC address;
- Packets to the FHRP MAC address are sent from the ToR switch over one of the LAG member links (not necessarily the link over which the packet from FHRP MAC address arrived), resulting in somewhat optimal load balancing toward FHRP MAC address.
- Whichever core switch receives the inbound packet to FHRP MAC address performs L3 forwarding.
As always, the devil is in the details: L3 switches might send the routed traffic from their hardware MAC address (not FHRP MAC address), thoroughly confusing devices with broken TCP stacks that prefer to glean incoming packets instead of using standard mechanisms like ARP.
Active/active FHRP behavior is nice-to-have if you’re satisfied with L3 forwarding on core switches. Just remember that all inter-subnet east-west traffic traverses the core even when the two VMs sit in the same hypervisor host.
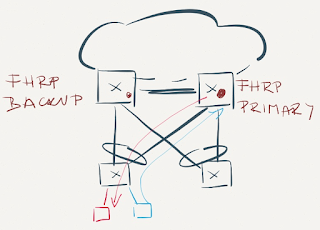
Inter-VLAN traffic flow with routing on core switches
The GLBP Hack
GLBP bypassed the single forwarder limitation with an interesting trick – different hosts would receive different MAC addresses (belonging to different routers) for the shared virtual router IP address.
While the trick might work well in original FHRP use cases (with large L2 domain between the hosts and the bank of routers), it’s totally useless in data center environments requiring L3 forwarding at the ToR switches:
- VM might get a MAC address from a random ToR switch (not the closest switch);
- VM is pinned to a MAC address of a ToR switch and sends the traffic to that same switch even when you vMotion the VM to a totally different physical location.
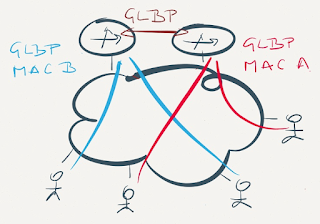
GLBP is useless in a data center fabric
Multi-FHRP hack, where each router belongs to multiple FHRP groups on each interface and end-hosts use different first-hop gateways, is almost identical (but harder to manage) than GLBP hack
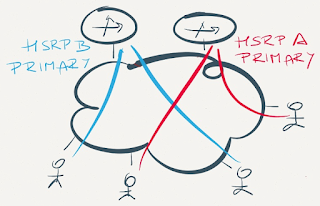
Multiple FHRP groups are no better than GLBP
More information
Got so far? Wow, I’m impressed. Here’s more:
- Data Center 3.0 for Networking Engineers webinar describes numerous data center-related technologies and challenges, including L2/L3 designs;
- Data Center Fabric Architectures webinar describes typical fabric architectures and vendor implementations;
Revision History
- 2023-02-01
- Removed references to long-gone products/startups.
- Added links to additional relevant blog posts.
You make this comment...
"The only way to reach this goal is to introduce layer-3 forwarding functionality into the top-of-rack (ToR) switches."
But, why not stated as L3 forwarding into the access layer switch, i.e. vswitch or TOR? :)
-Jason