We Just Might Need NAT66/NPT66 (and Not LISP)
My friend Tom Hollingsworth has written another NAT66-is-evil blog post. While I agree with him in principle, and most everyone agrees NAT as we know it from IPv4 world is plain stupid in IPv6 world (NAPT more so than NAT), we just might need NPT66 (Network Prefix Translation; RFC 6296) to support small-site multihoming ... and yet again, it seems that many leading IPv6 experts grudgingly agree with me.
The Problem
There’s plenty of multihoming going on in the current Internet without anyone being aware of it. Anyone using Internet for mission-critical applications (or business-grade cloud access) can get two Internet connections from two upstream providers and use pretty simple NAT tricks to use those connections in either active-standby or active-active mode. I’m personally aware of a few large multinational organizations using similar designs for remote office or retail access.
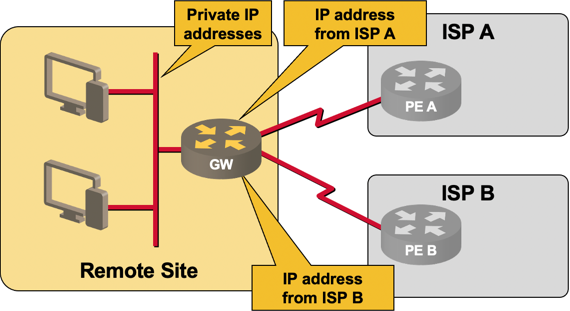
Simple small site multihoming
Using currently available low-end routers and existing IPv6 host stacks (with TCP stack without a session layer and broken socket API) you can solve the same problem in one of two ways in the IPv6 world:
BGP-based multihoming. Get a large chunk of provider-independent (PI) address space and an AS number, assign a /48 to every location, and run BGP with two upstream ISPs from every location.
With this approach anyone in Elbonia who’s willing to pay ASN and PI prefix tax (a few tens or hundreds € or $ per year) and a business-grade ISP connection to two Service Providers gets the chance to pollute routing and forwarding tables in every router in the default-free zone ... worldwide. Not something I’m looking forward to.
VPN-based multihoming. You use your own address space within the remote office site; the public address space assigned by the ISPs is used only to address tunnel endpoints. This design does not allow local Internet exit (all Internet traffic has to be shuffled over a VPN tunnel to a central hub site) – often a showstopper for companies that have widespread remote offices.
NPT66-based multihoming. Works in exactly the same way as NAT-based multihoming in IPv4, but translates only on the upper 64 bits of the IPv6 prefix. It’s NAT (so it’s evil), but at least it’s stateless.
Unicorn Tears and Other Solutions
There are a number of other solutions we could use, but they all require changes to the host IPv6 stack, so it’s not likely we’ll see them implemented any time soon.
SCTP and Shim6 are pretty old and well-known. SCTP requires application-level changes (due to broken socket API), Shim6 requires changes in the IPv6 stack.
IPv6 multihoming without IPv6 NAT is one of the emerging IETF drafts that try to address the problem (you should read at least the first few sections, where they admit you need NPT66) ... but yet again requires changes to the host IPv6 stack to work properly (but only in the source IP address selection policy code).
LISP would replace BGP-based multihoming with LISP-based multihoming (moving the customer prefixes into the LISP+ALT topology, which yet again uses BGP). This approach will probably work well once everyone deploys LISP (like: never?). In the meantime, you’ll need proxy-ITR/ETR routers (6to4 relays anyone?), resulting in suboptimal traffic flows and central choke points.
Summary
As much as I hate to admit it, NPT66 seems to be the most flexible solution for the small-site IPv6 multihoming problem we have today. I would love to see the host IPv6 stacks fixed, but I’ve learned a sad lesson from the history of NAT: once the networking McGyvers fix other people’s problems with layers of duct tape, everyone starts pretending the problem is gone and goes off chasing another squirrel.
More information
- Enterprise IPv6 – the first steps webinar gives you an overview of IPv6 technologies, 4-to-6 migration alternatives and design recommendations.
- Service Provider IPv6 Introduction is an introductory-level webinar targeting ISP environments.
- Building Ipv6 Service Provider Core webinar describes access- and core-layer technologies and designs.
All three webinars (and numerous others) are part of the yearly subscription.
Decisions like not allowing some form of NAT is, in my opinion, one of the main reasons the deployment of IPv6 was several years late.
Now we need a CPE implementing NPT66 ! (Cisco ?).
Also a good implementation of NAT64 (at CPE or Edge ?) will be a plus.
You can get NAT64 on ASR1K and MX-series routers and on many load balancers (ACE-30/Cisco, BIG-IP/F5, Brocade ...). There are also less-well-known large-scale carrier implementations (I think Ericsson might have one).
Perhaps I'm just revolted at the idea of NAT66 because I remember IPv4 before NAT & want that back so badly. I really don't like the idea of applications coming up with more duct-tape methods to get around NAT again. I'm looking at you, STUN.
How are we small enterprises supposed to connect to the internet locally? You just can't with the current IPv6 system. I will not even consider implementing IPv6 on my network until this is resolved.
NAT isn't evil. It is just another tool in my arsenal. It only becomes a problem when people try to fit a square peg into a round hole.
http://tools.ietf.org/html/draft-ietf-v6ops-ipv6-multihoming-without-ipv6nat-03
Read at least 3.3 (Problem statement), and I would strongly recommend reading the whole document.
I guess this is NAT66, but it seems like it is more a gateway/routing action than an addressing one, since the host identifier remains constant and you aren't getting the obfuscation that you typically get when using rfc1918 addresses in IPv4, since that gateway device is going to have a /64 assigned to it, which should be more than enough to do endpoint independent address mapping for a typical branch office or soho site.
Fast forward to today... with a smart flow-router, this seems really easy; and in the example of the branch office, would let you have out-bound link decision routing tables - Internet gets sent to the Internet, the corporate intranet gets sent down the VPN. Yeah, you spend more for the device, today, but that seems like a more sensible way to do things than to have any of the all or nothing scenarios you give as possible solutions. Because you are flow centric, you keep all the packets for a flow (or for a client or a destination or anything you can key on for persistence) going out the same link, so they all have the same public source address. The internal nodes all have three addresses, the link local address, and an address corresponding to each link's public IP space; DNS sorts out which address to use when.
You could set it all up with an f5 in about an hour, fwiw.
BTW, the IETF draft you quoted (draft-ietf-v6ops-ipv6-multihoming-without-ipv6nat-03) has one of the best descriptions of the need for NPT66. The only other reasonable alternative is changing host stacks and we all know we're years too late for that ... there are real people out there doing real work on Windows XP and IE6. They are ready for IPv6 ... as it was defined 5+ years ago. We had 15+ years to get it right ... and failed miserably.
Just my grumpy $0.02 :(
Bottom line, NAT66 doesn't seem like the horror you make it out to be; dealing with the internal LAN issues isn't something that we haven't already dealt with when running IPv6 LANs connected to the IPv4 Internet, and multihoming doesn't appear to be that big of a deal if you look at it (and gateway it) from L4 up.
However, it seems that what you're describing falls more under the PBR behavior (which is now available in IOS for IPv6 ... unless I got it all wrong again), in which case the source IPv6 address selection on the host remains unsolved problem.
Also, I see no problem implemented that on Linux, Windows might be able to do it, iDevices - no way.
Works for me, using that for quite some time now.
Don't make me sick with NAT66, come on :)
/sarcasm off..
Funny I was discussing this with a network architect here and he told me that we will need some kind of Nat in IPV6 too
Nonetheless, had the ISO prevailed IPv6 would have been DECNET 5. so we are thankful for the IETF for keeping ownership of IPv6. It took 15 years from IP to get past the multiprotocol world of IPX/DEC/SNA/LLCx/and Appletalk etl. all. to its adoption so I am confident IPv6 will too.
Yet one has to wonder had the ISO kept ownership of IPv6 would they have tied it into CLNS-ISIS natively and all this trill fabric multipath ISIS stuff of today would be moot.
As for the XP stacks they are done. IPv6 on XP is just as evil as NAT.
In the event of a non-bgp, PA-addressed site, hosts must recieve addresses from each PA block from ecah provider. The application is responsible for selecting the correct source address (try PA IP 1, if no joy in 2 seconds, switch to PA IP 2) or send simultanious requests from each PA IP and reset the last one to succeed.
There are unexplored solutions to this problem, and NAT is the old comfortable blanket full of bed bugs. We need to burn it, not cling to it.
To start with, it's not an application problem, it's a networking stack problem. The application cares about getting a session to the server; solving a broken networking stack/API problem in the application is as wrong as thrusting it onto the network.
IETF has been ignoring multihoming issues for more than a decade, in the meantime the OS vendors built what RFCs told them to build. Now that the OS stacks have been built and deployed (based on RFC specs), the IPv4 addresses are running out, and some people are finally deploying the academic architectures designed 15 years ago, we're "all of a sudden" rediscovering the problem.
As always, it seems the problem will be "solved" by implementing the easiest-to-implement kludge.
So does that mean NAT66 will force us to use a "private" ipv6 space for hosts behind the NAT? If so , dont we now lose the beauty of having every host reachable directly by everyother host?
Sorry for the ignorance, just curious about this issue.
With active/active uplinks, you have a "proper source address selection" problem.
With active/standby uplinks, you have either "proper source address selection" problem or "lack of fast renumbering" one.
PS: I'm no expert in these matters so feel free to correct me if you wish