Virtual Switches – from Simple to Scalable
Dan sent me an interesting comment after watching my Data Center 3.0 webinar:
I have a different view regarding VMware vSwitch. For me its the best thing happened in my network in years. The vSwitch is so simple, and its so hard to break something in it, that I let the server team to do what ever they want (with one small rule, only one vNIC per guest). I never have to configure a server port again :).
As always, the right answer is “it depends” – what kind of vSwitch you need depends primarily on your requirements.
I’ll try to cover the whole range of virtual networking solutions (from very simple ones to pretty scalable solutions) in a series of blog posts, but before going there, let’s agree on the variety of requirements that we might encounter.
We use virtual switches in two fundamentally different environments today: virtualized data centers on one end of the spectrum, and private and public clouds at the other end (and you’re probably somewhere between these two extremes).
Virtualized Data Centers
You’d expect to see only a few security zones (and logical segments) in a typical small data center; you might even see different applications sharing the same security zone.
The number of physical servers is also reasonably low (in tens, maybe low hundreds, but definitely not thousands) as is the number of virtual machines. The workload is more or less stable, and the virtual machines are moved around primarily for workload balancing / fault tolerance / maintenance / host upgrade reasons.
Public and Private Clouds
Cloud environment is a completely different beast. Workload is dynamic and unpredictable (after all, the whole idea of cloudifying the server infrastructure revolves around the ability to be able to start, stop, move, grow and shrink the workloads instantaneously), there are numerous tenants, and each tenant wants to have its own virtual networks, ideally totally isolated from other tenants.

The unpredictable workload places extra strains on the networking infrastructure due to large-scale virtual networks needed to support it.
You could limit the scope of the virtual subnets in a more static virtualized data center; after all, it doesn’t make much sense to have the same virtual subnet spanning more than one HA cluster (or at most a few of them).
In a cloud environment, you have to be able to spin up a VM whenever a user requests it … and you usually start the VM within the physical server that happens to have enough compute (CPU+RAM) resources. That physical server can be sitting anywhere in the data center, and the tenant’s logical network has to be able to extend to it; you simply cannot afford to be limited by the geography of the physical network.
Hybrid environments
These data centers can offer you the most fun (or headache) there is – a combination of traditional hosting (with physical servers owned by the tenants) and IaaS cloud (running on hypervisor-powered infrastructure) presents some very unique requirements – just ask Kurt (@networkjanitor) Bales about his DC needs.
Virtual Machine Mobility
One of the major (network-related) headaches we’re experiencing in the virtualized data centers is the requirement for VM mobility. You cannot change the IP address of a running VM as you move it between hypervisor hosts due to broken TCP stack (or you’d lose all data sessions). The common way to implement VM mobility without changes to the guest operating system is thus L2 connectivity between the source and destination hypervisor host.
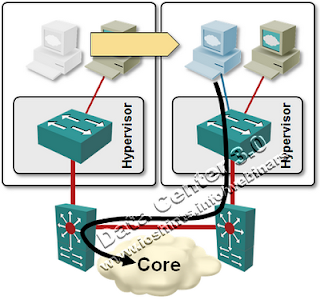
In a virtualized enterprise data center you’d commonly experience a lot of live VM migration; the workload optimizers (like VMware’s DRS) constantly shift VMs around high availability clusters to optimize the workload on all hypervisor hosts (or even shut down some of the hosts if the overall load drops below a certain limit). These migration events are usually geographically limited – Vmware HA cluster can have at most 32 hosts and while it’s prudent to spread them across two racks or rows (for HA reasons), that’s the maximum range that makes sense.
VM migration events are rare in public clouds (at least those that charge by usage). While the cloud operator might care about the server utilization, it’s simpler to allocate resources statically when the VMs are started, implement resource limits to ensure VMs can’t consume more than what the users paid for, and let the users perform their own workload balancing (or not).
Anything else?
If I’ve missed something important, if you disagree with my views, or would like to add your own, don’t hesitate – the comment box is just below the post.
I am not bashing Amazon at all. It is just one of the model you can implement a cloud. There are other models of creating a cloud where you can sell capacity to an end user and enforce SLAs on all subsystems (CPU / Memory / Disks / Networks) by using a mix of guarantees, shares, DRS, mobility etc etc etc.
As you said it depends. It really depends what you are doing. There isn't a one size fits all here. Some people call the latter the "Enterprise" way to do it whereas other people call the former the "Real Cloud" way to do things.
Honestly, I can't give a s**t about the definitions any more... I am just trying to stay on what customers want.
Massimo.