The all-or-nothing approach to OpenFlow was quickly replaced with a more realistic approach. An OpenFlow-only deployment is potentially viable in dedicated greenfield environments, but even there it’s sometimes better to rely on functionality already available in networking devices instead of reinventing all the features and protocols that were designed, programmed, tested and deployed in the last 20 years.
Not surprisingly, the traditional networking vendors quickly moved from OpenFlow-only approach to a plethora of hybrid solutions, and even the startups pushing OpenFlow-only model had to distribute control plane functionality to make their solutions work.
Please note that the blog post refers to OpenFlow implementations that might be obsolete – NEC stopped selling ProgrammableFlow, and Juniper implemented a more traditional approach to OpenFlow than what Dave Ward was telling us in 2011.
OpenFlow Deployment Models
I hope you never believed the “OpenFlow networking nirvana” hype in which smart open-source programmable controllers control dumb low-cost switches, busting the “networking = mainframes” model and bringing the Linux-like golden age to every network. As the debates during the OpenFlow symposium clearly illustrated, the OpenFlow reality is way more complex than it appears at a first glance.
To make it even more interesting, at least four different models for OpenFlow deployment have already emerged:
Native OpenFlow
The switches are totally dumb; the controller performs all control-plane functions, including running control-plane protocols with the outside world. For example, the controller has to use packet-out messages to send LACP, LLDP and CDP packets to adjacent servers and packet-in messages to process inbound control-plane packets from attached devices.

Source: Wikimedia Commons
{kind=link}
This model has at least two serious drawbacks even if we ignore the load placed on the controller by periodic control-plane protocols:
The switches need IP connectivity to the controller for the OpenFlow control session. They can use out-of-band network (where OpenFlow switches appear as IP hosts), similar to the QFabric architecture. They could also use in-band communication sufficiently isolated from the OpenFlow network to prevent misconfigurations (VLAN 1, for example), in which case they would probably have to run STP (at least in VLAN 1) to prevent bridging loops.
Fast control loops like BFD are hard to implement with a central controller, more so if you want to have very fast response time.
NEC was using this approach (with a few OpenFlow extensions), but quickly encountered inherent scaling limitations: a single controller can control up to ~50 switches and rerouting around failed links takes around 200 msec (depending on the network size). For more details, watch their Networking Tech Field Day presentation.
Native OpenFlow with extensions
A switch controlled entirely by the OpenFlow controller could perform some of the low-level control-plane functions independently. For example, it could run LLDP and LACP, and bundle physical links into port channels (link aggregation groups). Likewise, it could perform load balancing across multiple links without involvement of the controller.
Some controller vendors went down that route and significantly extended OpenFlow 1.1. For example, Nicira has added support for generic pattern matching, IPv6 and load balancing in Open vSwitch.
Needless to say, the moment you start using OpenFlow extensions or functionality implemented locally on the switch, you destroy the mirage of the nirvana described at the beginning of the article – we’re back in the muddy waters of incompatible extensions and hardware compatibility lists. The specter of Fiber Channel looms large.
Ships in the night
Switches have traditional control plane; OpenFlow controller manages only certain ports or VLANs on trunked links. The local control plane (or linecards) can perform the tedious periodic tasks like running LACP, LLDP and BFD, passing only the link status to the OpenFlow controller. The controller-to-switch communication problem is also solved: the TCP session between them traverses the non-OpenFlow part of the network.

Source: Wikimedia Commons
{kind=link}
This approach was commonly used in academic environments running OpenFlow in parallel with the production network. It’s also one of the viable pilot deployment models.
Integrated OpenFlow
OpenFlow classifiers and forwarding entries are integrated with the traditional control plane. Juniper planned to implement OpenFlow to inserts compatible flow entries (those that contain only destination IP address matching) as ephemeral static routes into RIB (Routing Information Base). Those static routes could be then redistributed into other routing protocols.
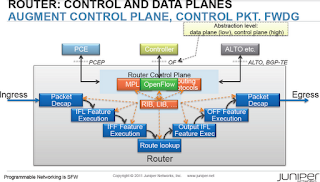
Going a step further, Juniper’s OpenFlow model presents routing tables (including VRFs) as virtual interfaces to the OpenFlow controller (or so it was explained to me). It’s thus possible to use OpenFlow on the network edge (on user-facing ports), and combine the flexibility it offers with traditional routing and forwarding mechanisms.
From my perspective, this approach makes most sense: don’t rip-and-replace the existing network with a totally new control plane, but augment the existing well-known mechanisms with functionality that’s currently hard (or impossible) to implement. You’ll obviously lose the vague promised benefits of Software Defined Networking, but I guess that the ability to retain field-proven mechanisms while adding customized functionality and new SDN applications more than outweighs that.
For more details on Juniper’s OpenFlow implementation, watch Dave Ward’s presentation from the OpenFlow symposium or a more detailed presentation he gave during the Network Field Day.
Disclosure: vendors mentioned in this post indirectly covered my travel expenses during the OpenFlow Symposium and Networking Tech Field Day, but nobody has ever asked me to write about their products or solutions.
First, OOB management is fairly common in DC environments (as you pointed out QFabric uses a similar approach), so this requirement is not a big deal. Second, I'm sure at least some the ONF players recognize the importance of "fast control loops" and we will see mechanisms supporting offload of these to dumb switches in OF1.x or 2.y. Third, as OF is still in its infancy, I would not worry too much about vendor extensions - if successful, they may eventually make it to the standard OpenFlow spec before we start building our "nirvana DC".
There's still an issue of communicating with the non-OF world, to which we may see some interesting solutions, Juniper's integrated approach being one of, especially when combined with BGP speaking DC edge enabling granular control of traffic flows in/out of the DC. For large distributed networks this could also provide the required inter-DC failure domain separation with a stable routing protocol implementation.