vMotion: an elephant in the Data Center room
A while ago I had a chat with a fellow CCIE (working in a large enterprise network with reasonably-sized Data Center) and briefly described vMotion to him. His response: “Interesting, I didn’t know that.” ... and “Ouch” a few seconds later as he realized what vMotion means from bandwidth consumption and routing perspectives. Before going into the painful details, let’s cover the basics.
The basics
vMotion is VMware’s technology that allows migration of live virtual machines from one physical server to another without losing VM state, its data or its LAN or SAN sessions. It’s not a new technology (the Usenix ’05 article contains lots of useful technical details) and even the competing products (Hyper-V) got similar functionality in recent releases.
vMotion by itself is useful, but additional functionality built on top of it makes it indispensable: with DRS, VM load can be spread dynamically across a cluster of physical servers and with DPM, all VMs running on a cluster are consolidated on a small number of servers in the off-hours and the unused servers shut down.
Bandwidth implications
Obviously, vMotion needs to transfer the whole VM memory image before the VM state can be migrated to the second server; expect a few gigabytes of data traversing your network. The data transfer usually doesn’t matter if the physical servers are close together, but if the VM image is transferred across the Data Center backbone or even across a WAN link, the load can become significant.
Depending on the server uplink utilization and the QoS requirements of your traffic you might want to consider the impact of vMotion even when the servers are close together. For example, if you use a fully loaded UCS chassis with only a few uplinks, you might want to configure QoS on the uplinks to ensure vMotion does not interfere with your regular traffic (hint: it’s easy to configure vMotion to run in a dedicated VLAN).
Routing implications
Obviously the moved VM has to retain its IP address if you want to retain its TCP/IP sessions (and it makes no sense to move a running machine if it loses all the sessions). You can easily guess what the “traditional” solution is: bridging between the source and the destination physical servers. When a VM is moved from one server to another but remains in the same VLAN, all it takes is a single packet sent from the VM to update the MAC address tables on all intervening switches.
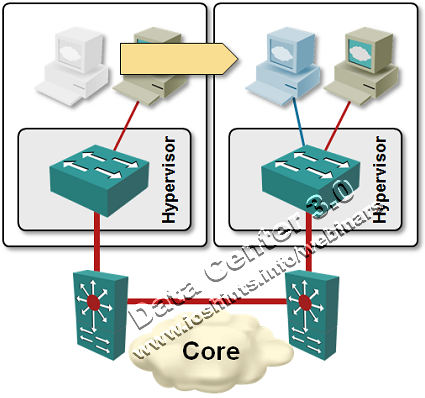
The implications of the same-VLAN requirement are manifold:
- You need a trunking link connecting the physical server with a switch.
- All servers have to have the same set of VLANs.
- All intermediate switches have to participate in all those VLANs.
- The server and switch configurations have to be synchronized (don’t forget, every VMware server has an embedded switch).
Net result: if you have a security-conscious environment where different applications reside in different layer-3 segments, you’ll end with a veritable VLAN sprawl.
Traffic flow implication
Every VM is connected to a number of network-layer and application-layer peers (routers, firewalls, database servers ...). As you move a VM, those connections are usually not moved and might significantly increase the amount of traffic flowing across your Data Center core.
For example, server VLANs commonly use a single default gateway established with a first-hop redundancy protocol (FHRP) like NHRPHSRP or GLBP.
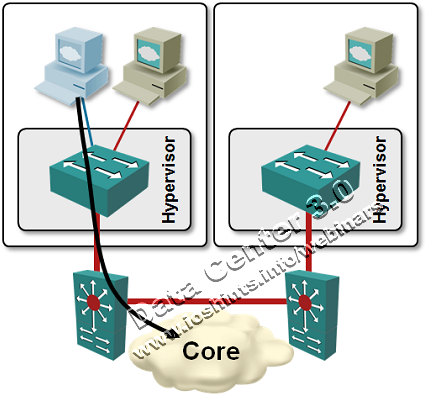
After the VM is moved, it still uses the same default gateway, causing its outbound traffic to go all the way back to the original switch.
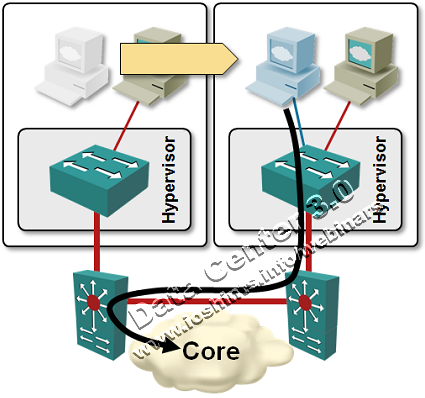
Notes:
- Traffic flow is optimal if the two switches use VSS or vPC.
- Very smart layer-2 filters can create two simultaneous FHRP groups on the same VLAN. This is an ideal solution if you’re looking for job security and late-night troubleshooting sessions.
Need more information?
If you’d like to know more about vMotion, there are literally tons of good articles on the Internet. Unfortunately, most of them are written from the server admin’s perspective.
For an overview of vMotion, related technologies and their impact on the network watch my Data Center 3.0 for Networking Engineers webinar (buy a recording or yearly subscription).
Very smart layer-2 filters can create two simultaneous FHRP groups on the same VLAN. This is an ideal solution if you’re looking for job security and late-night troubleshooting sessions.
smile
1) Do you believe that Hyper-v's Live Migration is up to par with vMotion? (I don't believe so)
2) Thoughts on Cisco's OTV to extend L2 between datacenters (and especially with vMotion)
#2: If you have to do long-distance bridging over IP, OTV is currently the best available technology.
However, in my opinion long-distance bridging makes little sense (more so when coupled with vMotion) and you should try to avoid it as much as possible.
This is one of my favorite unmentioned technology shortcomings today. If you have ever sat in a meeting with Cisco and server folks regarding the Nexus, OTV, and VM mobility, you will see their eyes light up while the networking folks shake their head.
One pie-in-the-sky solution for this was mentioned by Dino F. as a use case in part three of his Google tech talk regarding LISP (around 30:05):
http://www.youtube.com/watch?v=fxdm-Xouu-k
While this would require a newly designed FHRP and a signaling mechanism between a VM and the network, it is interesting nonetheless. :)
Sorry, but I think you meant "first-hop redundancy protocol (FHRP) like HSRP or GLBP" and not NHRP, or I don't know something interesting about NHRP :)
Can you explain a little bit more regarding the "avoid it as much as possible"-statement?
http://blog.ioshints.info/2010/09/long-distance-vmotion-and-traffic.html
As for long-distance bridging itself: each bridged VLAN is a single broadcast and security domain, which makes scaling pretty hard and prone to failures.
http://blog.ioshints.info/2010/07/bridging-and-routing-is-there.html
http://blog.ioshints.info/2009/05/vpls-is-not-aspirin.html
I actually got VM Mobility to work in my lab, and didn't need any changes inside the VM or the network when moving machines around.
So, LISP is good for you :-)