Policing or Shaping? It Depends
One of my readers watched my TCP, HTTP and SPDY webinar and disagreed with my assertion that shaping sometimes works better than policing.
TL&DR summary: policing = dropping excess packets, shaping = delaying excess packets.
Here’s the picture he sent me (watch the video to get the context and read this article to get the background details):
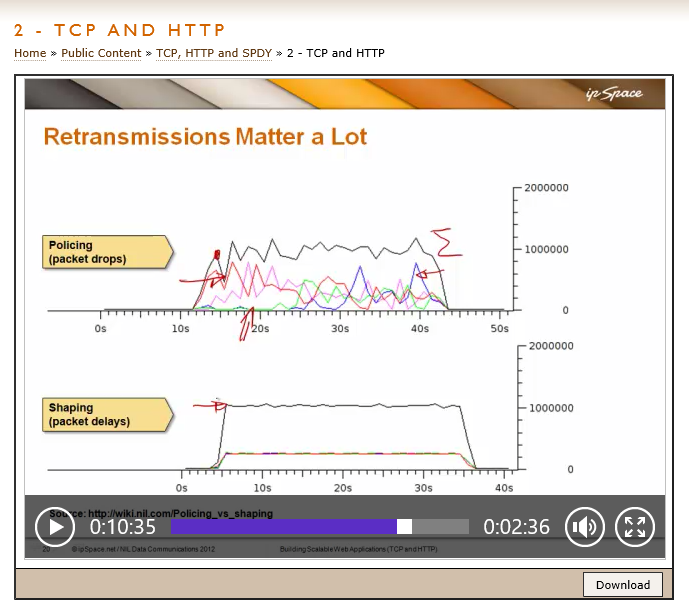
He observed that:
While to voice-over suggests that shaping is preferred, the total transmission rate of these two examples look about the same.
You might also notice how unequal the throughput is for individual TCP sessions. I doubt you’d want to be the happy owner of the green session.
Shaping is more aesthetically pleasing, but, one could argue that policing would avoid buffer bloat and achieve the same total throughput.
Jeremy provided not just throughput graphs but also goodput (iperf traffic) results in his blog post. iperf managed to push 840 kbps over a link policed at 1 Mbps and 962 kbps over a link shaped at 1 Mbps. Obviously shaping results in better goodput than policing, and equally obviously you have to configure reasonable limits for the shaping queues. For more details, please read Internet-Wide Analysis of Traffic Policing, an excellent Google Research paper.
Also, per-session WFQ within the shaping queue results in better TCP performance than FIFO+tail drop shaping queue.
Please don’t ask me what reasonable is. I’d guess that anything beyond bandwidth-delay product makes no sense, and I’d immediately agree with you that the current way of configuring output queues on most routers desperately needs improvements… or maybe it’s time to start asking for CoDel.
I would think, in this example, had Stretch run longer, he would eventually fill up his output queues anyway and you would start to see tcp rate changes.
Stretch connected two Ethernet segments with a router. RTT was below a millisecond, so one would hope that the queues would be pretty stable after 45 seconds of continuous transfer.
TCP should always be trying to increase its rate to see if it can run faster, but a big buffer slows this down by increasing RTT.
There are at least two signals TCP can use to figure out it should slow down: packet drops (example: TCP Reno) or increasing RTT (example: TCP Vegas). Some implementations also listen to ECN bits. Response to increased RTT is usually less drastic than response to packet drop (Disagree? Please write a comment!)
Finally, there are the bufferbloat disasters. While a lot of progress has been made in understanding what causes them and addressing the problem, it’s hard to solve the bufferbloat within the network if the host TCP stack uses huge TCP window sizes and sends way too large bursts. We’ll face bufferbloat challenges till the host TCP stacks are fixed.
FlowQueueCodel seems to be the network-side answer to bufferbloat, but it seems to require per-flow queues (no surprise there, so does WFQ), which are usually expensive to implement in hardware. OTOH, some software implementations work great.
The moral of this story is: there’s no right answer that works for everyone, and just because some implementations are badly broken (storing seconds worth of traffic in an output queue makes absolutely no sense, for example) it doesn’t mean that the idea of delaying packets instead of dropping them is a bad one.
More information
- Internet-Wide Analysis of Traffic Policing is an absolute must-read
- CoDel IETF draft is another one (and reasonably easy to understand)
- You should also explore the Bufferbloat site
However, shaping may introduce extra IP packet delay variation at each hop, so you may want to limit your shaping/policing pairs only to those links where a congestion could really happen.
Most network connections in LANs or core networks are oversized, so congestion would never happen there. On such links shaping/policing should not be configured.
If there is a policing, but no corresponding shaping, then I would write a material audit finding in my audit report... :-)