Rearchitecting L3-Only Networks
One of the responses I got on my “What is Layer-2” post was
Ivan, are you saying to use L3 switches everywhere with /31 on the switch ports and the servers/workstation?
While that solution would work (and I know a few people who are using it with reasonable success), it’s nothing more than creative use of existing routing paradigms; we need something better.
Why Are We Talking About This?
In case you stumbled upon this blog post by accident, I’d strongly recommend you read a few other blog posts first to get the context:
- What is layer-2 and why do we need it?
- Why is IPv6 layer-2 security so complex?
- Compromised security zone = game over
Ready? Let’s go.
Where Do We Have a Problem?
Obviously we only experience problems described in the above blog posts if we have hosts that should not trust each other (individual users, servers from different applications) in the same security domain (= VLAN).
If you’re operating a mobile or PPPoX network, or if your data center uses proper segmentation with each application being an independent tenant, you should stop reading. If you’re not so lucky, let’s move forward.
What Are We Doing Today?
Many environments (including campus, wireless and data center networks) use large layer-2 domains (VLANs) to support random IP address assignment or IP address mobility (from this point onwards IP means IPv4 and/or IPv6).
Switches in these networks perform layer-2 forwarding of packets sent within an IP subnet even though they might be capable of performing layer-3 forwarding.
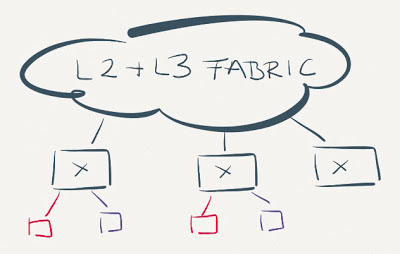
Data center fabrics perform a mix of L2 and L3 forwarding
The situation is ridiculous in extreme in environments with anycast layer-3 gateways (example: Arista VARP, Cisco ACI) – even though every first-hop switch has full layer-3 functionality and is even configured to perform layer-3 switching between subnets, it still forwards packets based on layer-2 (MAC) address within a subnet.
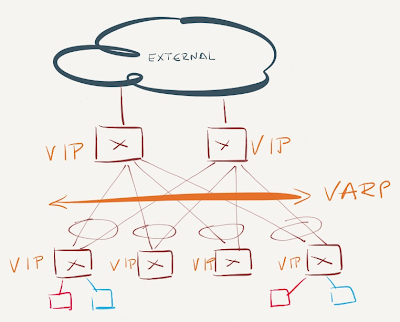
Anycast gateway implemented with Arista VARP
For further information on layer-3 forwarding in data centers and anycast layer-3 gateways, read these blog posts:
- Does optimal L3 forwarding matter in data centers?
- VRRP, anycast, fabrics and optimal forwarding
- Optimal L3 forwarding with VARP and active/active VRRP
- Arista EOS Virtual ARP (VARP) behind the scenes
What If…
Now imagine a slight change in IP forwarding behavior:
- Every first-hop switch tracks attached IP addresses;
- A switch creates a host route (/32 in IPv4 world, /128 in IPv6 world) for every directly-attached IP host;
- The host routes are redistributed into routing protocol, allowing every other layer-3 switch in the network to perform layer-3 forwarding toward any host regardless of host’s location in the network.
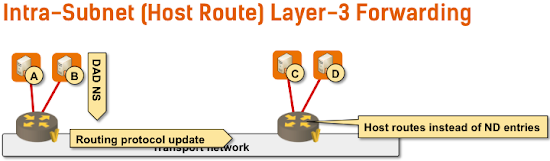
Intra-subnet layer-3 forwarding
Does this sound like Mobile ARP from 20 years ago? Sure it does – see also RFC 1925 section 2.11.
For more details, watch the recording of the IPv6 Microsegmentation presentation I had at Troopers 15, or the IPv6 Microsegmentation webinar if you need sample Cisco IOS configurations.
Will It Work?
It already does. Microsoft Hyper-V Network Virtualization, Juniper Contrail and Nuage VSP use this forwarding behavior in virtual networks. Cisco’s Dynamic Fabric Automation (DFA) used the same forwarding behavior in physical data center fabric, and Cisco ACI might be doing something similar. That’s also how some advanced EVPN deployments work. Not surprisingly, most of these solutions use BGP as the routing protocol.
Finally, if you’re using Cumulus Linux, try out the Redistribute Neighbor, which redistributes ARP cache into a routing protocol.
Interested in dirty details? You’ll find in-depth explanation in Overlay Virtual Networking webinar, which also includes step-by-step packet traces.
Revision History
- 2015-04-22
- Added a link to Cumulus Linux Redistribute Neighbor feature.
- 2023-02-01
- Removed links to (now obsolete) Cisco DFA
- Updated a link to Cumulus (now NVIDIA) documentation
Things get a bit tricky regarding ARP - Windows Server (at least) uses unicast ARP to check remote host reachability, so Hyper-V and Amazon VPC reply to ARP requests with MAC address of remote host. Juniper Contrail uses the same MAC address for all IP addresses.
I did some measurement and in our campus network, there are more then 3 unique IPv6 addresses per a computer in 24 hour period due to privacy extension. Considering campus with 5000 users, there will be more or less 15 000 of constantly changing routes. Which routing protocol is scalable enough to handle such large amount of prefixes and converges quickly? You are proposing BGP (iBGP?), but it means full mesh or route-reflector, convergence time could also be better etc. etc. :/
#2 - Existing L3 switches already have to handle that churn
#3 - Every routing protocol can carry 15K prefixes (OK, maybe not OSPF ;).
#4 - Update rates of 100/second are the norm on global Internet (see http://bgpupdates.potaroo.net/instability/bgpupd.html). Your iThingy users won't come anywhere close to that.
#5 - IBGP convergence times are not an issue these days. FIB update is the problem.
"what prevents an attacker to create a lot of MAC addresses/nd cache overflow" - in IPv4 world dhcp snooping, in IPv6 world unfortunately nothing as nd-snooping and other security features are missing or are not mature enough or are badly designed. Sigh.
If we take the use case of virtualized Data center with all servers running Hypervisor of some sort then the number of End-VMs you can support seems to be limited by TCAM /Route table size of ToRs which it looks like 128000.
I have a question - If number of VMs are less than 128K and it is what most of the large enterprises today have in their DC then why use Network Overlay technologies? I can think of only overlapping IP address as use case for using Network overlays. Any thoughts/comments on this?? I really don't see why one would use all these complicated Overlays since routing protocols are time tested and overly simple in terms of operations!!
You need a protocol between routers. Some people seem to prefer BGP as the solution to any problem. But the most natural solution here, for IGP routing, would be to use an actual IGP. IS-IS would do a fine job. Not much worse than BGP. And less prone to configuration/network-design problems than BGP. You could advertise /32s. Or you could introduce a new TLV to make a proper destinction.
It would be *minimal* work to actually implement this functionality into a proper IS-IS implementation. Just a small matter of programming.
You need a protocol for the routers to find out which EndStations are directly connected. In CLNS, that would be ESIS. In IPv4 you could indeed use ARP. In IPv6 you could use NDP. Or you could build a new proper host-router protocol (and use ARP until it catches on). With proper security/authentication, VRRP-like and DHCP-like functionality.
Of course all this will be impossible, because it reeks of CLNS. And therefor it must never ever be implemented in TCP/IP. Too bad, CLNS did it right.
Does this even make sense?
Any suggestions?
Would it make sense to limit host routes ("mobility" domain) to pair of ToR and advertise only /64 (in IPv6 world) with routing protocol to spine switches?
I would image that hosts would have to run a routing protocol (or maybe not?) and the actual host adress would be assinged to loopback interface with default routes to both ToR switches or am I thinking in a totaly wrong direction? :)
http://blog.ipspace.net/2015/08/layer-3-only-data-center-networks-with.html
Cisco has something similar in its DFA architecture (and probably in ACI as well). See also the links I published with the Cumulus podcast (link above) for even more details.
I had a query. let us assume there are two leaf's L1 and L2 and two spines S1 and S2. Now assume that there are independent switches (no fabric) and we are trying to have only l3 inside these connections.
A host connected to leaf L1 sends out an IP Packet. L1 routes the packet. Now let us assume that it reaches via the link to C2. Now C2 has to again route it and send it to L2 and L2 routes it to the end host H2 which was connected to it.
However, if we assume that the path from L1 to L2 is switched then we will have the same problem of L2 domains within the leaf-spine.
Is this understanding Correct?
Sincerely,
Sudarsan.D
In any case, in a pure L3 network, all switches have to do full L3 lookup. No multi-hop L2 anywhere. Problem solved.
When dealing with guests on each host, if each host injects a /32 for each guest, by the time the routes are on the spine, you're potentially well past the 128k route limit. I've read about overlays like vxlan but I still don't see how that would avoid the problem on the spines, as each spine would have to know about every /32, which could be on any one of the leaves below. Can you elaborate on how this can scale beyond 128k routes?
Most data centers don't have 128K guest VMs, and if you need more than that, you shouldn't be looking for solutions on public blog sites ;)
In a pure L3 only network where ever ToR/Spine switch does L3 forwarding, how is the routing to the end host done when the end host (VM) moves to another ToR and becomes silent as well.
To be clear, let us assume there are two ToR T1 and T2.
Host H1 is connected to T1 and H2 to T2. H1 and H2 are in different subnets.
IP connectivity happens between H1 and H2 by the fact that the ToRs and the spines do IP forwarding.
Now let us assume that the host H2 moves to ToR1 and is also silent as well.
Now how does ToR1 detect this condition? Without the dection ToR1 would route the packet to one of thespines, which would again route it to ToR2 and ToR2 would probably blackhole the traffic.
Please let me know
Sincerely,
Sudarsan.D
Here's a pretty good packet walk describing the nastier case (RARP instead of GARP): https://yves-louis.com/DCI/?p=1502
The link you mention assumes that the DCI interconnect is L2. My query is specifically when the DCI is only L3.(L3DCI).
Sincerely,
Sudarsan.D