Let’s Get Rid of the Thick Yellow Cable
Whenever I write about the crazy things vendors are trying to sell us, and the kludges we have to live with, I keep wondering, “Is it just me, or is the whole industry really as ridiculous as it seems?” It’s so nice to see someone else coming to the same conclusions, like Mark Burgess (the author of CFEngine and the Promise Theory) did in a lengthy essay on whether SDN makes sense.
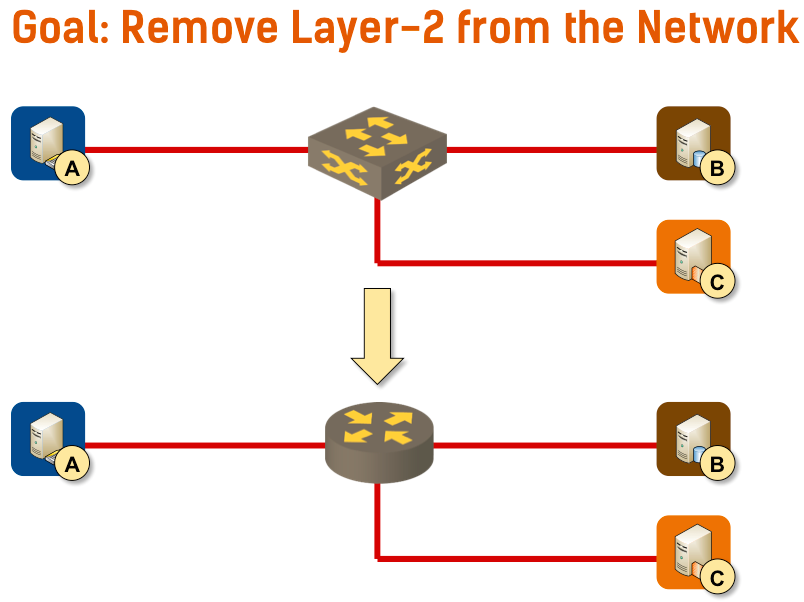
Long story short: there’s no need for layer-2 in the data center beyond the virtual link between a VM (or container) and the virtual switch. We should stop emulating the thick yellow cable.
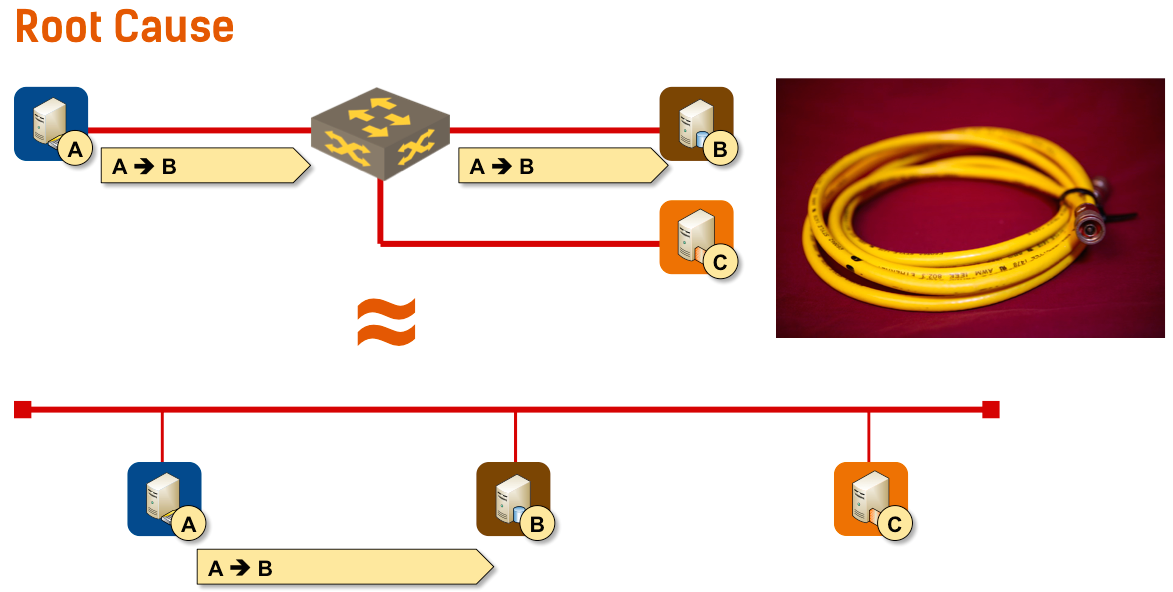
The diagram is from the IPv6 Microsegmentation Done Right presentation that I’ll present @ Troopers 2015. There are still a few seats left, so make sure you register ASAP. You can also attend the IPv6 Micro-segmentation webinar, but it would be so much better to meet you in person.
Instead of desperately trying to emulate 40-year-old technology, we should strive to make data center networks layer-3-only networks and use DNS for service location.
Interested? Go and read what Mark Burgess has to say on the topic.
Isn't he basically describing NAT/PAT without using those terms? Am I missing something here?
Like Mark wrote in his essay, you cannot dictate what your room# will be in the hotel. We should stop assigning overloaded meanings to IP addresses.
http://thenewstack.io/docker-acquires-sdn-technology-startup-socketplane-io/
See you are definitely not alone
Will only be a matter of time until they self service their own tenancy/privacy/group membership up the stack (ex. whether peer-to-peer encryption or identity based/certificate trust domains/etc.). By the time everyone finally deploys overloaded L2 architectures, app-owners will probably have moved on.
Anyway, exciting times. As always, thanks for sharing!
Or am I missing something?
Back in 2001 (i.e. long before VPLS), the group of IXP operators proposed to redesign L2 according to L3 best-practices - by replacing thick yellow cable emulation and all Spanning tree stuff with IS-IS based routing of ethernet packets. Guess what - no vendor was interested. When Radia Perlman in 2004 presented the first TRILL proposal to IEEE, it was - rejected.
Several years later, two next-gen L2 standards were finalized - TRILL (based on L3 principles) and SPB (enhanced STP). Yet worse, every major vendor implemented its own next-gen L2 solution, of course totally incompatible with any of the standards. In the meantime, hacks like M-LAG (vPC) were developed to workaround apparent defficiences of outdated L2 technology.
In such a mess, it's no surprise that people consider L2 unusable and try to avoid it whereever possible. Hypervisor vendors decided to fix the problem in their own domain by yet another method (VXLAN, NVGRE,...) but this requires new NIC hardware and only works in DC environment. As such it's no solution to the main problem, since advanced L2 is needed in every LAN to get rid of thick yellow cable emulation and STP limitations.
Just FYI, in September 2014 we implemented TRILL-based infrastructure in the Slovak Internet eXchange. After 5 months of production, our experience shows that even though TRILL delivers standard L2 interface on the edge ports, inside it operates on exactly the same principles as any L3 network, utilizing field-proven IS-IS protocol for ethernet frame routing and TTL & RPF checks to prevent network meltdown.
So decent L2 technology definitely exists today - but the main problem is that the networking industry is unable to converge on single technical solution due to commercial reasons. This couldn't be fixed by resorting to L3.
"I see people arguing for a dynamic infrastructure. That is wrong thinking. Infrastructure and foundations are meant to be stable. What you build on top of that can be dynamic."
L2 overlays came from VMs moving or being spun up wherever there was free compute. It needed L2 because somewhere else another application or network element like a FW or LB was setup based on that VM/service having a specific IP. That's the crux of the issue.
The L2 overlays are getting better. Vendors are solving tromboning using anycasted default GWs, VXLAN can work with L3 directly into a VRF instead of just building a L2 overlay. VXLAN-GPE supports direct v4/v6 encapsulation. We have moved the underlay from L2 to L3.
However it will take an orchestration system to redirect endpoints as needed, or at least reprogram DNS entries if that's a valid option. Contextream has a solution based on NVO3 overlays coupled with LISP. So LISP takes care of the endpoint moving behind another IP address. However LISP doesn't have great support, so maybe DNS is the answer, along with more intelligent upstream devices which don't care what IP something is at. Junos Contrail is a L3 overlay, not a L2 overlay, and does so by using host routing over tunnels with a VNID/MPLS label as an identifier. A firewall instance doesn't need to be in the same subnet as the end host, it just needs to know the tunnel to get to it. Now it would be easier without tunnels altogether, but we aren't there yet.
your post intrigues me...
How can you get rid of L2 when you have remote sides that need DHCP over public internet .. or when you run hotspots ?