Exception Routing with BGP: SDN Done Right
One of the holy grails of data center SDN evangelists is controller-driven traffic engineering (throwing more leaf-and-spine bandwidth at the problem might be cheaper, but definitely not sexier). Obviously they don’t call it traffic engineering as they don’t want to scare their audience with MPLS TE nightmares, but the idea is the same.
Interestingly, you don’t need new technologies to get as close to that holy grail as you wish; Petr Lapukhov got there with a 20 year old technology – BGP.
The Problem
I’ll use a well-known suboptimal network to illustrate the problem: a ring of four nodes (it could be anything, from a monkey-designed fabric, to a stack of switches) with heavy traffic between nodes A and D.
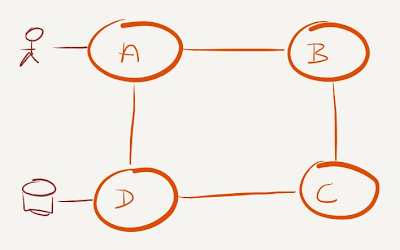
A suboptimal data center fabric
In a shortest-path forwarding environment you cannot spread the traffic between A and D across all links (although you might get close with a large bag of tricks).
Can we do any better with a controller-based forwarding? We definitely should. Let’s see how we can tweak BGP to serve our SDN purposes.
Infrastructure: Using BGP as IGP
If you want to use BGP as the information delivery vehicle for your SDN needs, you MUST ensure it’s the highest priority routing protocol in your network. The easiest design you can use is a BGP-only network using BGP as a more scalable (albeit a bit slower) IGP. EBGP is better than IBGP as it doesn't need an underlying IGP to get reachability to BGP next hops.
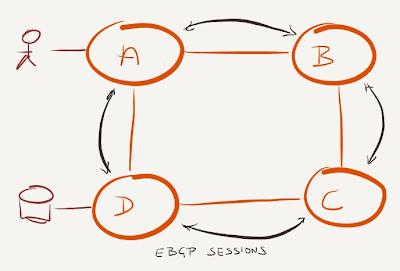
Build EBGP sessions between data center switches
BGP-Based SDN Controller
After building a BGP-only data center, you can start to insert controller-generated routes into it: establish an IBGP session from the controller (cluster) to every BGP router and use higher local preference to override the EBGP-learned routes. You might also want to set no-export community on those routes to ensure they aren’t leaked across multiple routers.
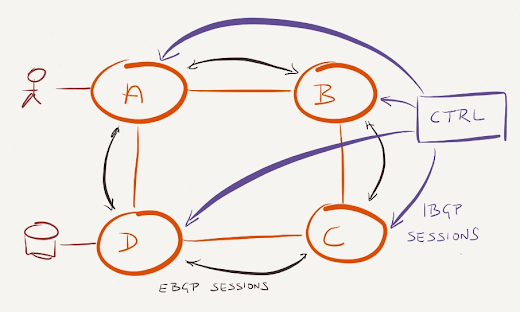
Add a BGP controller to the mix
Obviously I’m handwaving over lots of moving parts – you need topology discovery, reliable next hops, and a few other things. If you really want to know all those details, listen to the Packet Pushers podcast where we deep dive around them.
Results: Unequal-Cost Multipath
The SDN controller in our network could decide to split the traffic between A and D across multiple paths. All it has to do to make it work is to send the following IBGP routing updates for prefix D:
- Two identical BGP paths (with next hops B and D) to A (to ensure the BGP route selection process in A uses BGP multipathing);
- A BGP path with next hop C to B (B might otherwise send some of the traffic for D to A, resulting in a forwarding loop between B and A).
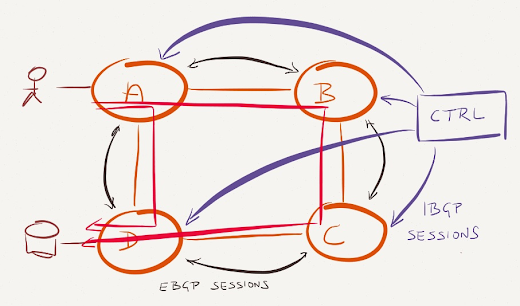
Controller-driven unequal-cost multipath
You can get even fancier results if you run MPLS in your network (hint: read the IETF draft on remote LFA to get a few crazy ideas).
More information
- Routing Design for Large-Scale Data Centers (Petr’s presentation @ NANOG 55)
- Use of BGP for Routing in Large-Scale Data Centers (IETF draft)
- Centralized Routing Control in BGP Networks (IETF draft)
- Cool or Hot? Lapukhov + Nkposong’s BGP SDN (Packet Pushers Podcast)
I have some ideas regarding using BGP for "exception routing":
- There is no great need to run eBGP as IGP. A real IGP (ospf...) will be more suitable. As far as (i/e)BGP is configured with a higher preference in all routers, SDN injected routes will always take precedence.
Advantages are:
- Faster IGP
- No need to use BGP communities to limit the scope of the injected BGP routes (No BGP peering is needed between the routers)
- More "standard" deployment as using a real IGP as an IGP :) :)
- Easy to introduce to a network already in production...
http://www.cs.princeton.edu/~jrex/papers/rcp-nsdi.pdf
However, the key to SDN is (or should be) *what* do you tell your routers and switches, not so much *how* you tell them. The *what* is what implements the use case, the actual deployment scenario. Unfortunately the *how* has received most of the hype and attention (hello OpenFlow).
Marten @ Plexxi
@martent1999
So, when I deploy a new service, I want to select 'so much' compute, 'so much' storage, and 'so much' networking. Submit this request and have the operating systems and applications come online, the network segments with routers, firewall policy, and logging become available; and destroy it all when finished.
Compute and storage have already enabled the consumer to hold the keys to service delivery, networking needs to catch up.
I also need to ask, in your diagrams above, why would you ever want traffic to traverse B and C unless there is a failure?
To answer your question: Why wouldnt you want to traverse B and C if doing so can double your global DC throughput or if A<-->B<-->C<-->E provides a low delay path required by and dedicated to some applications or the opposite or, or...?
It s all about the use case!
One of the challenges for SDN, in my opinion, is that network resources are much more complex than compute or storage resources in that raw bandwidth is not the only (or even in many cases the most important) quantity to optimize. As others have said, it is all about the use case.
I can't find anything except SDN
Of course you should start by asking yourself "Do I REALLY need routing by source?"
Imagine you have the IDS in C node of the above scenario. You can have a list of "bad" IPs and redirect all the traffic to this IDS with the BGP Controller.
In the other hand, imagine you think that some IP of your internal network is infected, if you can route by source with the BGP Controller, you could redirect all traffic to the IDS.
1) You know of the IP -> ASN mapping via boostrap file (static config)
2) Switches initiate iBGP sessions to Anycast IP's of the controller(s), and controller responds with BGP OPEN reflecting the incoming ASN number
Of course, people who are scared of MPLS-TE also will not like LFA, and for that matter are typically afraid of doing complex routing tricks with BGP.
Years ago I played around with a simple datacenter topology where each rack was a different confederation Sub-AS. I know confederations are totally out of style these days but seems like it would work as well in this instance.
What you describe with regards to next-hop control, etc. is exactly how Internap's MIRO routing control works at their edge, and has since probably the late 90s. Slightly different scenario since they are using it to control outbound traffic paths on upstream transit providers. Their MIRO controller is internally written and has lots of knobs in order to optimize the routing and place constraints on paths, would be cool if they open sourced it.
Juniper QFabric architecture is also based on BGP...
While I'm agnostic to it, I know like we've seen in the comments most feel source routing has to be a part of any SDN solution. In reality on my network today I source route high priority traffic by using different RSVP LSPs on the network.
I think in a DC context using Segment Routing along with a scalable distribution protocol like BGP may work extremely well. In the future a protocol like I2RS may be a better fit than BGP as a control protocol.
Thanks