Hyper-V Network Virtualization (HNV/NVGRE): Simply Amazing
In August 2011, when NVGRE draft appeared mere days after VXLAN was launched, I dismissed it as “more of the same, different encapsulation, vague control plane”. Boy was I wrong … and pleasantly surprised when I figured out one of the major virtualization vendors actually did the right thing.
TL;DR Summary: Hyper-V Network Virtualization is a layer-3 virtual networking solution with centralized (orchestration system based) control plane. Its scaling properties are thus way better than VXLAN’s (or Nicira’s … unless they implemented L3 forwarding since the last time we spoke).
The architecture
From the functional block standpoint, Hyper-V Network Virtualization looks very similar to VXLAN. The virtual switch (vmSwitch) embedded in Hyper-V does simple layer-2 switching, and the Windows Network Virtualization (HNV) module, the core building block of the solution, is inserted between an internal VLAN (virtual subnet; VSID) and the physical NIC.
Interesting trivia: HNV is implemented as a loadable NDIS filter (for the physical NIC) and inserted between the vmSwitch and the NIC teaming driver.
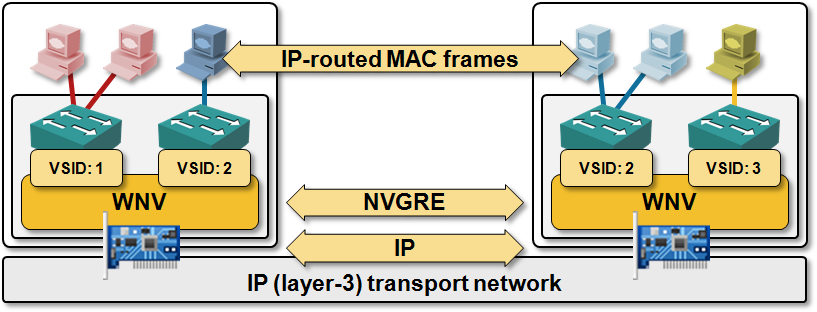
The major difference between VXLAN and HNV module is their internal functionality:
- HNV is a full-blown layer-3 switch – it doesn’t do bridging at all; even packets forwarded within a single virtual network (VSID) are forwarded based on their destination IP address.
- HNV is not relying on flooding and dynamic learning to get the VM-MAC-to-VTEP mappings; all the forwarding information is loaded into the HNV module through PowerShell cmdlets.
Like OpenFlow-based solutions (example: Nicira’s NVP), Hyper-V Network Virtualization relies on a central controller (or orchestration system) to get the mappings between VM MAC and hypervisor IP address and VM IP and VM MAC address. It uses those mapping for deterministic packet forwarding (no unicast flooding) and ARP replies (every HNV module is an ARP proxy).
Net result: you don’t need IP multicast in the transport network (unless you need IP multicast within the virtual network – more about that in a follow-up post), and there’s zero flooding, making HNV way more scalable than any other enterprise solution available today.
How well will it scale?
From the scalability perspective, Hyper-V Network Virtualization architecture seems to be pretty close to Amazon’s VPC. The scalability ranking of major virtual network solutions (based on my current understanding of how they work) would thus be:
- Amazon VPC (pure layer-3 IP-over-IP solution)
- Hyper-V Network Virtualization (almost layer-3 solution using MAC-over- GRE encapsulation)
- Nicira’s NVP (layer-2-over-STT/GRE solution with central control plane)
- VXLAN (layer-2-over-IP solution with no control plane)
- VLAN-based solutions
Breaking with the past bad practices
And now for a few caveats inherent in the (pretty optimal) Hyper-V Network Virtualization architecture:
- Since the HNV module performs L3-based forwarding, you cannot run non-IP protocols in the virtual network. However, HNV already supports IPv4 and IPv6, both within the overlay virtual network, and in the transport network. Let me repeat this: Microsoft is the only major virtualization vendor that has shipping IPv6 virtual networking implementation.
- You cannot rely on dirty tricks (that should never have appeared in the first place) like clusters with IP address sharing implemented with ARP spoofing.
I’m positive that the lack of support for dirty layer-2 tricks will upset a few people using them, but it’s evident Microsoft got sick and tired of the bad practice of supporting kludges and decided to boldly go where no enterprise virtualization vendors has dared to go before.

A huge Thank you!
Matthias Backhausen was the first one to alert me to the fact that there’s more to NVGRE than what’s in the IETF draft.
There’s plenty of high-level Hyper-V/HNV documentation available online (see the More details section below) but the intricate details are still somewhat under-documented.
However, my long-time friend Miha Kralj (we know each other since the days when Lotus Notes was considered a revolutionary product) introduced me to CJ Williams and his team (Bob Combs and Praveen Balasubramanian) graciously answered literally dozens of my questions.
A huge Thank you to all of you!
More details
Microsoft resources:
- Network Virtualization technical details
- Hyper-V Network Virtualization Gateway Architectural Guide
- NVGRE: Network Virtualization using Generic Routing Encapsulation
- Step-by-Step: Hyper-V Network Virtualization
For step-by-step hands-on description, read Demystifying Windows Server 2012 Hyper-V 3.0 Network Virtualization series by Luka Manojlović:
However, since Hyper-V Network Virtualization uses PowerShell-based configuration, you can always write your own orchestration system which can be as redundant as you wish.
Or, as Ivan notes you could build your own...
So SDN VxLAN will become a reality very soon. Sorry Mr John Chambers, looks like a very bad news ! If Cisco is loosing control on virtual switch, they will loose associated control with their ToR switches ... snif ;)
The last time I was briefed on Nicira's NVP, they still relied exclusively on L2 forwarding and although they managed to reduce the impact of flooding, they still had to do it.
With VMware/Nicira NVP, the goal is to recreate the properties of the physical network into a logical, virtual network. This means a "logical switch" provides the same L2 service model to the virtual machines attached to it, as would a physical switch. So, yes, this means broadcasts and multicasts are forwarded to where they need to go. No new caveats and restrictions placed on the application architect.
Where would you rank it in the scalability toplist?
I understand that LISP is currently not in any Hypervisor or vSwitch (nor is BGP for that matter, and that is currently the controlplane that most of the NVO3 mailing list is cluttered with ), but i do think it could be usefull to consider it: take a look at http://blogs.cisco.com/getyourbuildon/a-unified-l2l3-ip-based-overlay-for-data-centres-another-use-case-for-the-location-identity-separation-protocol/ for some considerations.
Another observation is that todays virtualization vendors often nothing but a centralized SDN style controlplane, touching all Virtual Switches simultaneously.
I found it interesting that the VL2 whitepaper from 2009 (Microsoft + Amazon.. Notice James Hamilton's name at the top), which was all IP basically told us all what direction they were going 3 years ago.
http://research.microsoft.com/apps/pubs/default.aspx?id=80693
The trick was the integration into the hypervisor's networking stack (the proxy ARP and security) needed to be supported. This was doable enough for a single company, Amazon, in their own contained environment. A Microsoft environment, which is not nearly as contained, but closer than the wild west of roll-your-own cloud (or the larger eco-system of VMware based networking vendors), to me also has a fair shot. Your thoughts about 'less deployed' means faster support?
Notice the whitepaper's focus on making the core network CHEAP and easy. I assume this will not be great news for core big-iron switching and routing feature road maps.Would you agree? Broadcom and Intel are looking better and better in this world. Everyone has relatively cheap ECMP flow routing these days.
I would think another loser here are the early adopters who bought the solid work product of deep hypervisor network integration with last year's API. They are likely going to get edged out by 'hypervisor vendor lockin features', like 'behind the curtain SDN'. There will always be nuances outside vendors will have to come to partner with the hypervisor vendor to support. This is step one in a long road, and the owner of the VM guest MAC address will dictate the edge, and the technologies deployed at the edge. Do you agree?
Also, we've solved the network infrastructure problem in the meantime - every single vendor knows how to build Clos fabrics, and with something-over-IP virtual networking we no longer need fancy core forwarding technologies.
Arise the world of the new networking overloads VMware and Microsoft. It's a bit of a scary thought.
http://www.meetup.com/openvswitch/
they seem to have regular network virtualization tech talks by industry leaders as well as technical workshops
#2 - You might want to be polite and use your real name
#3 - Just because people use L2-based HA tricks doesn't mean those tricks are OK. Anyhow, if you so badly need them, you could still implement them in NVGRE with orchestration tool assistance.
#4 - NVGRE kernel module provides IP routing functionality with static routes (including default route), so you can push traffic toward IP next hop.
#5 - The only way to get traffic out of a virtualized network today is through a VM-based L3-7 appliance ... like with most other overlay network solutions.
#6 - HW vendors are promising HW- or appliance-based NVGRE gateways (in this case, Dell/Force10 and F5, not sure about Arista).
Thanks for the reply. I didn't mean to come off as angry or impolite. I do take issue with your dismissal of industry standard practices and endorsement of a not-fully-functional implementation, so maybe that is the source of my apparent frustration.
The issue is that in a VMM 2012SP1 environment, we are forced to only use NV policies VMM allows so #4 is kind of moot. So, without a VMM-integrated gateway, there is no way to have a virtual network interface with a non-virtual one via static routes in the NVGRE rule-set. No gateways are available as of right now. Some are coming in a few months, others later this year (re: #6).
For #3, do you mean that VRRP is not OK? (http://tools.ietf.org/html/rfc5798)
I agree that there are some 'dirty' L2 tricks that some HA software does (looking at you, LVS's DR), but there are plenty of legitimate and RFC supported reasons to have flexible MAC-IP mappings. This is why ARP is a critical protocol in IPv4. It would be nice if we could have long ARP timeouts due to highly static IP-MAC mappings, but there are a lot of advantages to be had doing it the current way too. Network Virtualization does not really nullify them, IMO, so I feel that it should have the necessary flexibility without having a 3rd party update policy sets.
#5, 100% agree. So, why was the technology released before such things are available? :P
The last problem I've had with the specific way NVGRE was implemented in VMM is that the VM that has a NIC on a virtual NVGRE network has to get DHCP from the HV switch for that NIC, and that DHCP has a default gateway. That means that I can't have a single-subnet 'private' virtualized network between VMs combined with a traditional network for Internet traffic (such as a web server VM that would use NVGRE to talk to it's storage and DB and a traditional network on which requests come in and replies go out). Is there a way to get around this? (if only DHCP clients respected DHCP route options, but alas). The only way I can think of is a proxy/LB in front like F5 or HAProxy.
My point is that, NVGRE is a good concept, and works well as a core technology. I agree that it seems more scale-able that VxLAN. I think the issue I have is more in how it was released: lacking important supporting functionality.
Thanks,
Alex
We're in total agreement regarding the out-of-sync release of NVGRE Hyper-V module (which I like) and orchestration software (which I haven't seen yet but might not like once I do ;) Same thing happened with the first release of vCloud Director and vShield Edge ... but vShield Edge got infinitely better in the next release, and I hope VMM will go down the same path (hope never dies, does it).
As for "industry standard practices" I couldn't disagree more. Just because everyone misuses a technology in ways it was never intended to be used to fix layer 8-10 problems doesn't make it right.
DNS and SRV records were invented for a reason, and are the right tool to solve service migration issues. I know everyone uses ARP spoofing (oops, dynamic IP-to-MAC mapping ;) to be able to pretend the problem doesn't exist, but that still doesn't make it right. The "R" in VRRP stands for "Router", not "Cluster member" for a good reason ;))
As for your last problem, I have to think about it. Could you send me more details?
Thank you!
Ivan
Thanks,
Anonymous Alex (I may have to use this henceforth)
(http://channel9.msdn.com/Events/TechEd/Europe/2013/MDC-B380)
1. In WS2012.R2, the HNV module was moved up into the vSwitch itself from where it previously resided on top of the LBFO module. This allows L3/GRE encap/decap activities within the switch itself, subsequently allowing all extension modules to act on both physical/virtual (fabric/tenant) addresses. This provides the hypervisor/switch extensions full visibility into both networks.
2. In VMM2012.R2, a specific, multi-tenant gateway role was designed. this allows HA VMs to act as a routing gateway for up to 100 tenant networks (at least in preview). This does mean that access to external/shared resources is now flowing through an additional hop/server before hitting the network unencap, but this also allows multisite bridging between DCs, tenant sites, networks, etc.
3. as to offloads: several NIC vendors (mostly merchant silicon: intel & broadcom) are integrating NVGRE endpoints into their NICs. This will allow all existing offloads to function as expected without any additional change to hardware.
Matthew Paul Arnold
mpa
Any thoughts on creating multipoint NVGRE (mNVGRE)?
It seems like this would be NHRP + NVGRE implemented in a switch or router.
If you then had some mechanism for mapping a NVGRE TNI into a VRF, it seems like you would have the basis for a non-MPLS VPN-based way to extend virtual networks over an arbitrary IP WAN, encapsulated in an overlay, but without resorting to VRF-Lite complexity.
If you could get it in a switch, from say, Cisco, Juniper, or Arista, it seems to me you have a big portion of the things you need to directly extend NV over an IP-only network without resorting to strapping expensive routers into your design just for the encapsulation function.
there seems to be another version of NVGRE draft published by murari et al as of feb 24, 2013
is it possible to compare the two drafts and comment on any changes or enlighten us on the new publication ?
Kind Regards,
Anand Shah
http://datatracker.ietf.org/doc/draft-sridharan-virtualization-nvgre/?include_text=1
http://www.ietf.org/rfcdiff?url2=draft-sridharan-virtualization-nvgre-01
http://www.ietf.org/rfcdiff?url2=draft-sridharan-virtualization-nvgre-02
As you can see from the diff results, nothing substantial has been changed.
Ofcourse we have the option to use any router/firewall vm appliance with 1 vnic in the virtual network and another vnic in the physical network. There are plenty of them that can do the job with much much less resources compared to the Windows RRAS, but still does not scale very well for public cloud. Especially for clients with a single VM it becomes too much overhead.
On the hardware side i've found only F5 and iron networks to offer something.
In F5 what I understand is that they just add NVGRE functionality in their existing load balancers, so it's not a pure virtual to physical network gateway. Especially when the clients are not requiring load balancer, but rather NAT (static and/or overload), RA VPN and Site-2-Site VPN.
Iron networks are also quite undocumented on the "multi-tenancy" topic. Nobody says how many tenants and what a cloud provider needs to use it.
I will be very happy if anyone shares some additional knowledge and experience.
I completely disagree with that. Even though you have -NextHop switch but that can only work for a PA Address (provided you have routing rules created) or a VMM gateway implemented on the network.
-NextHop is available with CustomerRoute and ProviderRoute cmdlets but none of them work to forward non-NVGRE traffic to an external router.
Thanks!
Thanks!