… updated on Thursday, May 5, 2022 07:47 UTC
BGP Next Hop Processing
Following my IBGP or EBGP in an enterprise network post a few people have asked for a more graphical explanation of IBGP/EBGP differences. Apart from the obvious ones (AS path does not change inside an AS) and more arcane ones (local preference is only propagated on IBGP sessions, MED of an EBGP route is not propagated to other EBGP neighbors), the most important difference between IBGP and EBGP is BGP next hop processing.
It’s best to explain BGP next hop processing through a set of examples; mine will be based on the following small network:
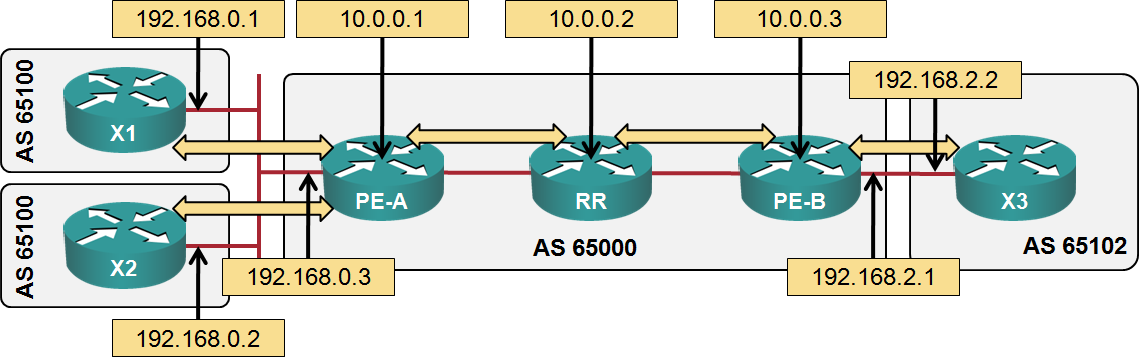
Sample network diagram
And since this post became way too long, here’s a rough table of content:
- Originating BGP routes
- Route reflectors
- EBGP rules and forwarding optimization
- IBGP rules and design guidelines
BGP Next Hop of a Locally Originated Route
When a router originates a BGP route configured with a network router configuration command or through route redistribution (redistribute router configuration command), it sets the BGP next hop to the IGP next hop (the same value you’d find in the IP routing table). BGP next hop is set to 0.0.0.0 for routes with unknown next hops – connected interfaces, static routes to null 0 or summary routes configured with aggregate-address router configuration command.
You can set the BGP next hop of a locally originated BGP route to any value you like with a route-map applied to network, redistribute or aggregate-address router configuration command. But remember: just because you could doesn’t mean that you should.
Changing Missing Next Hop in BGP Updates
When a BGP route with missing next hop (next-hop = 0.0.0.0) is sent to BGP neighbors, the BGP next hop is set to the source IP address of the BGP session.
Example: PE-A originates BGP prefix 10.0.1.0/24 based on a static route to null 0. When it sends this BGP prefix to X1 and X2, BGP next hop is set to 192.168.0.3. BGP next hop in update sent to RR is 10.0.0.1.
If you use common BGP design recipes (IBGP sessions configured between loopback addresses and EBGP sessions configured across directly-connected subnets), and the BGP next hop is unknown, the BGP router advertises its loopback address as BGP next hop on IBGP sessions, making BGP table resilient to topology changes inside your network.
For routes with known next hops, the router applies standard IBGP/EBGP next hop processing rules (see below) when sending the BGP updates to its neighbors.
Route Reflector Cannot Change BGP Next Hop of Reflected Routes
Large autonomous systems use BGP route reflectors. With a few exceptions, BGP route reflectors cannot change any attribute of the routes they reflect. The BGP next hop advertised by an edge router is thus propagated unchanged across the whole AS.
Exceptions:
- Cisco IOS allows setting next-hop to self on reflected routes with the neighbor next-hop-self all configuration command. See Changes in IBGP Next Hop Processing blog post for more details.
- You can change BGP next hop on a route reflector with an inbound route-map. Don’t do this outside of a CCIE lab.
Example: Prefix 10.0.1.0/24 originated by PE-A is propagated by RR to PE-B. BGP next hop is still 10.0.0.1.
BGP Next Hop Is Set to Router’s Own Address on EBGP Sessions
The internal details of an AS should not influence packet forwarding between autonomous systems (and we cannot assume that a router external to our AS would know our internal details). The BGP next hop is thus changed to router’s own IP address (source address of the EBGP session) in outgoing EBGP updates.
Example: When PE-B sends BGP prefix 10.0.1.0/24 (with next-hop 10.0.0.1) to X3, it sets BGP next hop to 192.168.2.1.
Next Hop Optimization on EBGP sessions
EBGP next hop is not changed if the BGP next hop in the BGP table belongs to the same IP subnet as the EBGP neighbor to which the update is sent. This rule ensures optimum packet forwarding in partially meshed EBGP deployments (example: internet exchange points).
Example: X1 sends BGP prefix 172.16.0.0/16 to PE-A. Next hop is set to the source address of the EBGP session between X1 and PE-A (192.168.0.1). When PE-A propagates the BGP prefix to X2, it does not change the next hop (X1, PE-A and X2 are in the same subnet).
You can disable the EBGP next hop optimization with neighbor next-hop-self router configuration command. This command is particularly useful in partially meshed multi-access networks (Frame Relay, ATM, Phase 1 DMVPN, private VLANs), see Using BGP in Phase 1 DMVPN Networks post for more details.
Example: Assuming neighbor 192.168.0.2 next-hop-self is configured on PE-A, the BGP next hop of all BGP routes sent to X2 from PE-A will be 192.168.0.3 and the traffic between X1 and X2 will flow through PE-A.
BGP Next Hop Is not Changed on IBGP Sessions
All routers within an autonomous system are assumed to be able to reach the same set of subnets (advertised through IGP). Consequently, when an AS edge router propagates external BGP prefixes to internal BGP peers, it does not change the BGP next hop.
The only exception to this rule is a router doing load balancing across multiple EBGP paths (as configured with maximum-paths configuration command). In that case, the BGP next hop is set to router's IP address on IBGP updates so the IBGP peers send the traffic to the originating router which can then do EBGP load balancing (added on 2019-09-19 based on input from Denis).
Example: X1 sends BGP prefix 172.16.0.0/16 with next hop 192.168.0.1 to PE-A. When PE-A propagates that prefix to RR, the BGP next hop is still 192.168.0.1. When the same prefix is reflected to PE-B, the next hop is still unchanged. PE-B therefore needs IGP path toward 192.168.0.0/24 or it cannot forward the traffic toward 172.16.0.0/16.
As with EBGP sessions, you can force the AS edge router to advertise its own IP address as the BGP next hop in IBGP updates with neighbor next-hop-self router configuration command applied to all IBGP sessions (I would usually use an IBGP peer session and peer policy template to simplify my configuration).
Example: X1 sends BGP prefix 172.16.0.0/16 with next hop 192.168.0.1 to PE-A. Assuming neighbor 10.0.0.2 next-hop-self has been configured on PE-A, the BGP next hop of the BGP route sent to RR will be 10.0.0.1.
IBGP Next Hop Design Rules
You can design IBGP in your autonomous system in two fundamentally different ways:
- IBGP routes point to external BGP next hops (default behavior)
- IGBP routes point to loopback interfaces of AS edge routers (next-hop-self is configured on IBGP sessions on AS edge routers).
If you don’t change the BGP next hop on AS edge routers, you have to propagate external subnets with your IGP. You can either configure external subnets as passive interfaces or redistribute them into your IGP. The two methods are almost identical if you use IS-IS; OSPF is a slightly different story. Flap of a passive OSPF interface causes full SPF run, whereas addition or removal of an external route (type-5 or type-7 LSA) results in partial SPF run. Redistribution of external subnets is thus preferred if you use OSPF.
However, it’s never a good idea to allow external events (like link flaps in your access network) to influence the stability of your core IGP. Using next-hop-self on AS edge routers (and changing the external next hops into edge router’s loopback address) is thus almost always the preferred design.
Summary
Saravanan posted an excellent table summarizing the BGP next hop behavior in a comment that got thoroughly mangled. Here it is (slightly edited):
| Scenario | Typical use case | Next hop in BGP table | Next hop sent to peers | Comments |
|---|---|---|---|---|
| Locally originated routes to both IBGP and EBGP peers | Connected interfaces or static routes with null0 next hop (blackholing) | 0.0.0.0 | Source address of the BGP session (source address of BGP packets sent by this BGP speaker) | Outgoing interface address if update-source is not used, else the value specified in update-source configuration. |
| Received routes sent to IBGP peers | Redistributed IGP routes, EBGP routes, or Static routes with valid/non-null next hop | Next-hop advertised by IGP or EBGP | Next-hop value from BGP table is advertised to IBGP peers. | You can override BGP next hop with next-hop-self or set next-hop (route map) configuration. |
| Received routes sent to EBGP peers where the EBGP peer IP address is not in the same subnet as the BGP next hop | Redistributed IGP routes, IBGP routes, EBGP routes, static routes with valid/non-null next hop | Next-hop advertised by IGP, IBGP or EBGP | Source address of the EBGP session | Outgoing interface address if update-source is not used, otherwise the value specified in update-source configuration. |
| Received routes sent to EBGP peers where the EBGP peer IP address is in the same subnet as the BGP next hop | Redistributed IGP routes, IBGP routes, EBGP routes, static routes with valid/non-null next hop | Next-hop advertised by IGP, IBGP or EBGP | BGP next hop is not modified – this is called EBGP next hop optimization or third-party next hop. | Next-hop value in BGP table is advertised as-is unless you configured next-hop-self or used set next-hop in a route map. |
| Route-reflector reflecting IBGP routes | IBGP routes only | Next-hop advertised by IBGP | BGP next hop is not modified | While it’s discouraged in BGP RFC, some implementations allow you to change next hop on reflected routes |
Further Reading
- Can We Trust BGP Next Hops (Part 1)?
- Can We Trust BGP Next Hops (Part 2)?
- Real Life BGP Route Origination and BGP Next Hop Intricacies
- What is a BGP RIB failure
- Can BGP Route Reflectors Really Generate Forwarding Loops?
Revision History
- 2022-05-05
- Added a summary table
Isn't MED actually propagated on EBGP routes?
Firstly, for leaking the edge link IP prefixes into IGP. A while ago, it made total sense to either change the next-hop to self or leak edge prefixes into BGP, to maintain reachability to provider managed devices at customer premises. This ensured network stability, to some extent. Nowadays, the requirements for fast convergence based on BGP NHT/PIC may dictate that edge link prefixes are leaked into IGP, for the purpose of fast event propagation. Furthermore, preserving the eBGP next-hop has some useful accounting implications, e.g. when exporting BGP next-hop in Netflow and looking to construct "external" traffic matrix. And network stability could be still controlled by using exponential event dampening (low-pass filtering).
Secondly, using redistribution no longer has advantage of "faster SPF" over type-1 LSA injection with the introduction of iSPF (invented in ARPANet!) to both OSPF/ISIS. Even without iSPF, SPF takes insignificant time of overall convergence process on modern CPU's - the majority of time is spent updating distributed forwarding tables after a change. Furthermore, redistribution might be even considered dangerous due to type-5 LSA's having larger flooding scope (there have been well-known precedents with that), not to mention that type-5 LSAs consume more memory and create more flooding overhead (less of concern, though).
Thirdly, changing next-hop to self on a route-reflector *may* be required even in production network if you need to ensure that RR is in the forwarding path to avoid route deflection (not the best design, though). This operation is also a key component for building hierarchical LSPs using BGP-based label propagation for overlay LSPs.
Regards,
Petr
Excellent post. Loved it! Really brought closure to the previous post. Thanks so much.
Will
Just to add a minor point for other readers, the "Next hop optimization on EBGP sessions" is also known as the "third-party next-hop" feature. :)
also found 2 nice linkz about SPF...
http://routingfreak.wordpress.com/2008/03/04/shortest-path-first-calculation-in-ospf-and-is-is/
http://routingfreak.wordpress.com/2008/03/06/the-complete-and-partial-spf-in-is-is/
I just ran into an issue I was not expecting that made me search on google about BGP routes with next-hop resolved through another BGP routes.
In my case an iBGP route's next-hop was resolved through another iBGP route. Both routes were installed in the routing table. The next-hop itself was reachable (ping/traceroute). However the destination was not: when debugging with 'debug ip packet', the router picked a loopback as the source (instead of the outgoing interface) and then declared the packet unroutable. Making the next-hop known through IGP fixed the problem.
Did you ever run into such an issue ? I could not find any explanation for it. My release is 12.4(15)T10.
Thanks for all the great information you share on your site.
Cheers,
Mat
No, I've never run into such an issue, I never tried to do something like that.
I am still surprised that the routes were installed in the routing table though ! It's a strange logic to install a route in the RIB and then decide that it is not valid.
Thanks,
Mat
Can we say it like this?
In EBGP, the next hop address is changed as the routes are passed to the neighbor routers. At last when the routes reach an IBGP, the next hop address is kept as the last EBGP routers address?
Simply, EBGP will update the next-hop address as the routes are passed to the neighbor routers but IBGP will NOT update the next-hop address as the routes are passed to the neighbor routers?
We have to go to the each router inside IBGP network and run the command "next-hop-self" to inform the next downstream router that "handover the packet to me" to reach the destination network ???
Next hop will be changed on EBGP session __unless_ the neighbor's IP address is in the same subnet as the current next hop.
Next hop will NOT be changed on IBGP session __unless__ you specify next-hop-self, which you'd do only on the AS boundary (usually you want to use IGP to control intra-AS routing toward BGP next hops).
Then there are the weird cases including 'next-hop-unchanged' for inter-AS MPLS/VPN or setting the next hop to a bogus value for remote-triggered black holes ;)
As for pulling your hair - we all went through that phase when faced with BGP.
The BGP feature "EBGP session __unless_ the neighbor's IP address is in the same subnet as the current next hop" may be enabled because in Multi-access environments the BGP routers may need to pass the packets one or two extra hops.
What I meant was in EBGP Multiaccess environments all the other routers in a subnet are reachable from any router, but may not be BGP neighbors. This may cause additional hops?
Am I right Sir?
Thank you very much...
Great post!
However can you please summarize what does it exactly mean by "Next-Hop Optimization on eBGP sessions". Spent my past 3 hours looking for an explanation but could not find anything satisfactory.
Thanks!
Sometimes you need to think about a problem, draw a bit, and get your hands dirty in a lab instead of looking around... or as someone said "you can observe a lot by just watching" ;)
tried to summarise with a table in html format, but it is not reflected as a table, so deleted the original content.
Managed to recover your excellent summary table and made it part of the blog post. Thanks a million!
Thanks Ivan. There is one typo in the scenario column of last-but-one row - "EBGP peer IP address is not in the same subnet as the BGP next hop"; should have been "same subnet" instead of "not".
Thank you, fixed.
IS the AS in top left corner, AS 65001 (it may have a typo as it is shown to have AS 65000)?
Yeah, one of those autonomous systems should have a different AS number... but everything works as explained even if they have the same AS number assuming PE-A does not do AS path checks on outbound updates (Cisco IOS doesn't IIRC)
I have a one question. If we have a scenario: AS with 2 Route reflectors, which have iBGP peering between those RRs. Should there be a next-hop-self command on the iBGP peering between Route reflectors? Or what is the design recommendation and why ? I've run into an issue if the next-hop-self command is not used.
The correct answer depends on the platform you're using, but assuming you're working with Cisco products, keep in mind that "next-hop-self" changes the next hop of EBGP routes (which is probably what you have to have in your design), but not of reflected routes.
Searching for "route reflector next hop site:blog.ipspace.net" will probably produce a few additional useful hits.