Controlling BGP Convergence Time
Articles » BGP as High-Availability Protocol » Controlling BGP Convergence Time
One of the features that qualifies this solution for mission-critical environments is the predictability of the convergence time. Although many people still believe that BGP is an extremely slow-converging routing protocol, with the appropriate tuning and feature, you could easily get end-to-end convergence time below a few tens of milliseconds. Let’s analyze the mechanisms that allow us to reach these results.
BFD – Bidirectional Forwarding Detection
All BGP peering communications are based on TCP sessions and controlled with timers more oriented to stability and scalability than a fast session failure detection. Fortunately, most modern BGP implementations work with BFD (Bidirectional Forwarding Detection) - a perfect fit for a session monitor. BFD is a lightweight and simple echo/echo-reply protocol based on UDP that monitors the mutual peer reachability and brings down the BGP session after a configurable number of missed replies.
The packet rates are configurable but platform dependent, typical values are 10x3 (10 ms interval and 3 lost packets needed for session-down detection) or 100x3. I personally suggest 10x6 values for critical environments or a more relaxed 50x6 in other environments. With these values the expected fault detection time is about 60ms or 300ms respectively. These are the worst cases, as a possible failure of the physical interface is usually immediately reflected with teardown of the BGP session.
However, the resulting fast converge time applies only to the devices involved in the link failure. We must also ensure that the topology change will be propagated and trigger routing protocol convergence in the WAN backbone and data center infrastructure.
BGP Tuning – Fast Failover and Delayed Update
As already mentioned, we can solve the typically slower RIB->FIB convergence time observed in most firewalls by reducing the routing information. However, some firewall vendors have safer default timers more focused on stability than fast convergence. In our design, the routing information is tightly controlled and minimized, and therefore these timers can be safely reduced to optimize the convergence time and reduce the routing propagation delay.
Note that if you have configured the BGP as indicated in the previous post, the backup firewall already has the routing and forwarding table ready for the failover, and does not require any update. A fast routing update is required (for example) on the primary firewall node in case of an inside interface failure to quickly propagate the updates and trigger the convergence of the WAN backbone that should start using the backup firewall node.
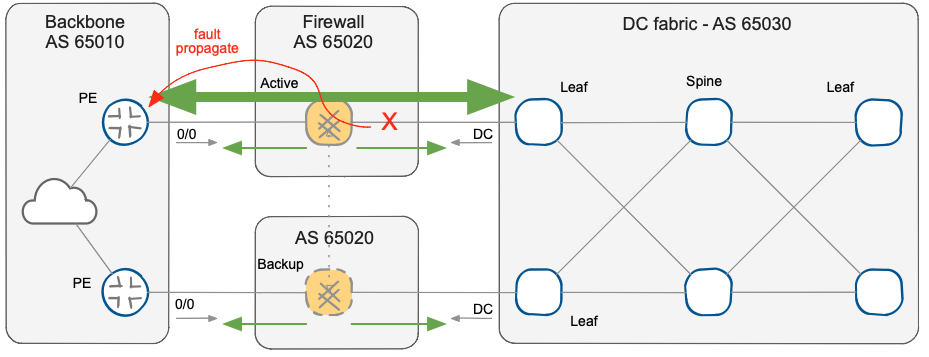
Fault propagation from inside interface to WAN backbone
Modern switches and routers typically do not have route table convergence problems: recent BGP implementations are event-based and do not introduce any delay from the moment a next-hop becomes unavailable to the moment a best-path selection process start. The use of BFD to monitor BGP session, and the directly attached firewall device therefore makes this sequence of events almost immediate.
Now that we have analyzed the convergence aspects of the individual devices, it’s time to move to the overall convergence time and interactions between devices.
BGP Best External and Add-Path
The original behavior of BGP is to propagate only the selected best path within the autonomous system to create uniform convergence and reduce the RIB size on all devices. This is also true in our scenario, and like most large networks, our data center or WAN backbone may use route reflectors (RR).
Please note that the leaf switch connected to the backup firewall node has the backup BGP path as an alternate path, but it is not used nor propagated to its BGP neighbors.
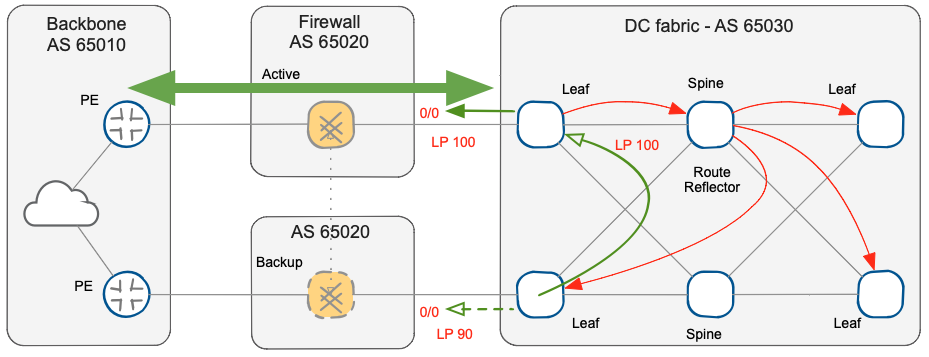
Propagating BGP default route to BGP route reflector and leaf switches
A failure in the primary firewall chain causes the disappearance of the default-route on the “designated primary" leaf and triggers a new convergence process:
- Withdrawal of the default-route from primary switch towards the RR;
- Subsequent withdrawal messages sent from RR to all other leafs.
- The backup default-route becomes immediately active on the backup leaf;
- Backup leaf immediately propagates the new best default route to BGP route-reflectors;
- BGP update then cascades to all the remaining leafs.
As a result, two complete BGP update propagation and convergence processes are required to install the new routing path on all devices.
You can activate best-external advertisement on the backup leaf to minimize the convergence process and the resulting convergence times. This feature enables the advertisement of best external BGP routes to internal BGP peers, even when the external BGP route is not the best path.
In this scenario, the backup default route is distributed to BGP route reflectors and all the remaining leafs even if it does not become active on any device. In fact, each device applies the BGP best-path algorithm independently, with the final result dependent on the different BGP Local Preference values imposed at the AS edge.
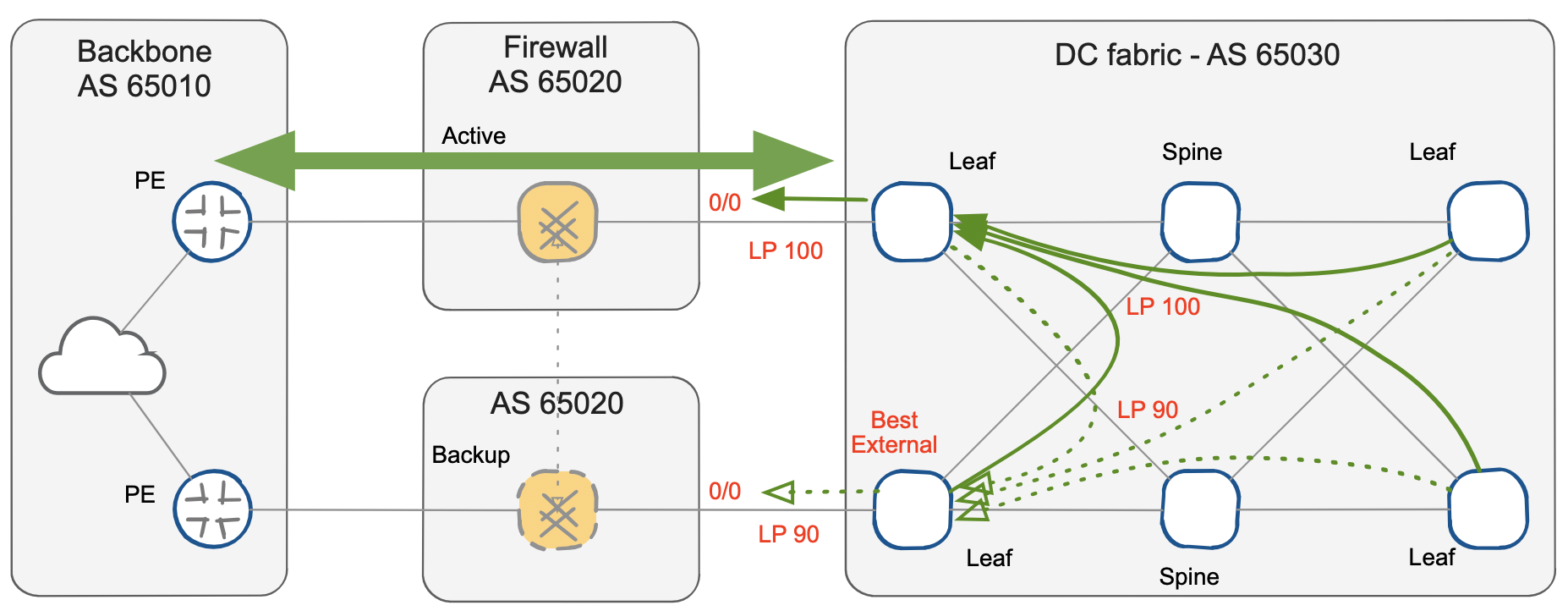
Alternate BGP paths gained with BGP Bext External
However, the advantage of this action is evident in the event of a fault of the primary firewall node: the first withdrawal removes the best-path on all the leafs, resulting in immediate installation of the designated backup path which is already present in the BGP RIB.
With this simple operation, we have more than halved the convergence time. As an collateral bonus, the use of BGP Best External (combined with BGP Add Path as needed - see below) allows us to verify the availability of the backup BGP path on all the leafs.
Total leaf failure results in the same behaviour. In that case, the undelay routing protocol detects the loss of BGP next hop representing the leaf switch, and the convergence time depends on the IP fabric or data center underlay routing design.
Keep in mind that the coexistence/propagation of primary and backup paths on route reflectors is not automatic: when they arrive to a BGP route reflector they are both iBGP prefixes and BGP Best External feature does not help in this case. If you’re using EVPN or L3VPN Address Family (AFI/SAFI) for your IP routing, it’s sufficient to assign different Route Distinguishers (RD) to each leaf; if you’re using plain IP routing, it’s necessary to use BGP Add-Path (RFC 7911).
Finally, the same optimization must also be performed in the WAN backbone, where (compared to high performance data center switches), the routing load and BGP Route Reflector hierarchy can have the greatest influence on overall convergence times.
Comparing BGP Convergence with Traditional Layer-2 Convergence
Now let’s compare the BGP-based solution with a traditional layer-2 solution based on FHRP (First Hop Redundancy Protocol). The proposed Layer-3 solution separates firewalls from data center hosts with a layer-3 boundary, making any firewall status changes transparent to data center hosts. BGP provides an “in-band” control-plane that checks the status of all links and devices in the forwarding path and selects the primary and backup paths. The total time required for a complete failover depends exclusively on BFD timers plus BGP state propagation delay.
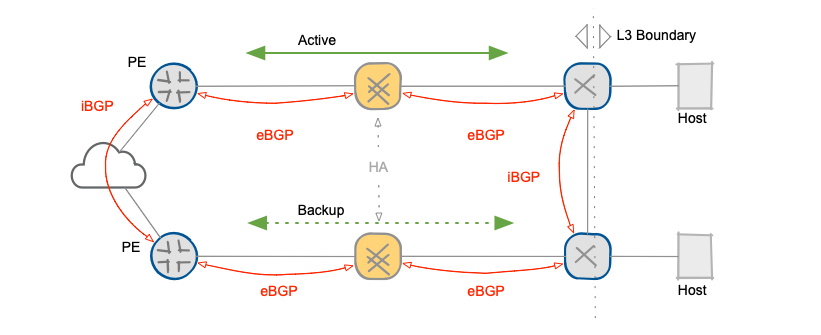
Layer-3 boundary between data center hosts and firewalls
A traditional layer-2 solution based on FHRP and static routing must rely on firewall clustering, and usually follows interface states and possibly some external probes (ping). In case of firewall failure the new master node will send GARPs (Gratuitous ARP) packets to trigger a layer-2 convergence on the shared segments. The convergence time depends on several independent factors, including convergence time of the layer-2 segment (which might depend on the number of devices in the segment).
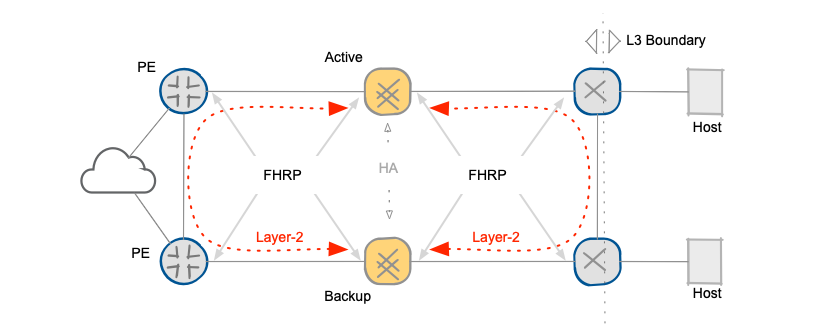
FHRP-based convergence
As the backup path is not continuously probed (like it is in the BGP-based solution), it’s hard to guarantee the correct functioning of the whole secondary path - the end-to-end connectivity can only be verified after the failover is complete. The convergence time and the failover success are thus non-deterministic.
Where to Use This Solution?
An advanced solution requires appropriate skills of the operations team and is thus not automatically suitable for every environment. Also, not everyone needs 50ms convergence time… but most everyone needs a reliable system and the proposed BGP-based solution is rock-solid are relatively simple.
The ideal applications for this solution include:
- Mission critical systems where reliability, rapid convergence and maintenance without service interruption are required.
- Firewalls distributed across multiple data centers (this solution works without a stretched layer-2 segment).
- High-availability solution with more than two nodes, even when they are distributed across different data centers
However, always keep in mind that the best solution might be the best fit for your environment if the your firewalls don’t support the required functionality, or if you experience resistance from other groups involved in the project.
This article is a summary of ideas Nicola used in multiple network designs. You can reach Nicola through his web site and engage him directly or through ExpertExpress service.