Bufferbloat Killed my HTTP Session… or not?
Every now and then I get an email from a subscriber having video download problems. Most of the time the problem auto-magically disappears (and there’s no indication of packet loss or ridiculous latency in traceroute printout), but a few days ago Henry Moats managed to consistently reproduce the problem and sent me exactly what I needed: a pcap file.
TL&DR summary: you have to know a lot about application-level protocols, application servers and operating systems to troubleshoot networking problems.
Henry immediately noticed something extremely weird: all of a sudden (in the middle of the transfer), my server sent destination unreachable ICMP reply and stopped responding to TCP packets.
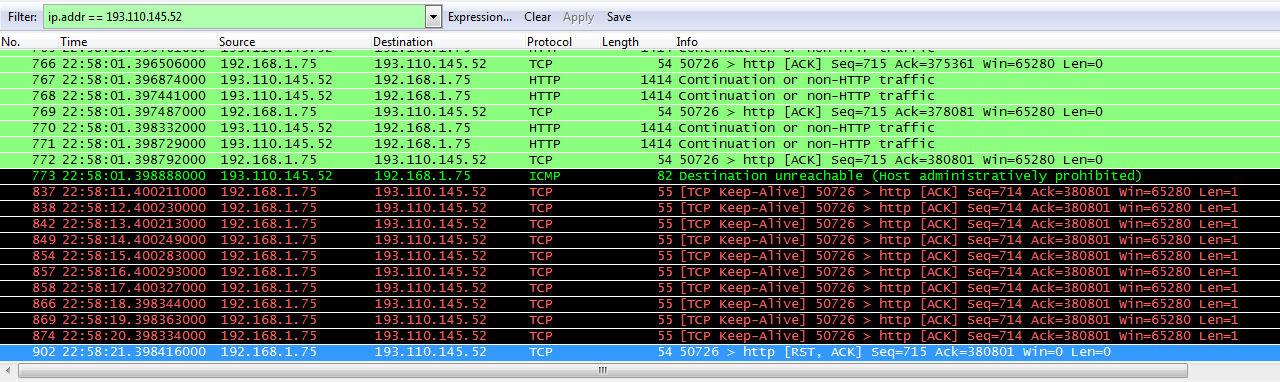
I was totally stumped – the only module on my web server that could generate administratively prohibited ICMP reply seemed to be iptables, so it looked like the web server dropped the TCP session without sending TCP RST or FIN (weird) and the iptables module subsequently rejected all incoming TCP packets of the same session.
The pcap file showed plenty of retransmissions and out-of-order packets (it looks like there really are service providers out there that are clueless enough to reorder packets within a TCP session), but there was no obvious reason for the abrupt session drop, and the web server log files provided no clue: all requests sent by Henry’s web browser executed correctly.
The only weird clue the pcap file provided was the timing: session dropped approximately 17 seconds after the transfer started, which was unpleasantly close to a 15-second timeout I vaguely remembered from one of the web server configuration files. A quick search found the only parameter that seemed to be relevant:
$ ack 15 conf*/*
conf/httpd.conf
89:KeepAliveTimeout 15
The KeepAliveTimeout specifies how long a web server keeps an idle HTTP session open, so it might be relevant… but why would it kick in during the data transfer?
I thought the answer could be bufferbloat: excessive buffering performed in various parts of the TCP stack and within the network. It looked like my web server managed to dump the whole video file into some buffers and considered the transfer completed in seconds. When the browser failed to send another command within 15 seconds (because it was still busy receiving the data), the web server decided it was time to close the idle HTTP session.
Based on that assumption it was easy to implement a workaround: increase the KeepAliveTimeout to 60 seconds. Seems like it solved the problem (I also added “send Connection: close header on long downloads” to my bug list).
It’s probably not that simple
I’m still trying to understand what exactly Henry experienced. After all, there are plenty of people all around the world accessing my web site over low-speed lines (thus downloading individual files for minutes) and none of them experience the same symptoms. Henry might have accessed my web site through a transparent web proxy that buffered too much data, or it might have been something completely different.
Have you experienced something similar? Write a comment!
One point that does make sense is Linux (by default) ratelimits certain ICMP (including unreach) per target, to 1 per second. Hence why the screenshot doesn't show more than one ICMP for all those incoming packets. http://linux.die.net/man/7/icmp
I didn't understand the red lines at the bottom either. Doesn't the ICMP quote the TCP/IP headers, get passed to the transport layer, and terminate the connection immediately? . Hmm, it's claimed that at least Linux clients treat ICMPs for established TCP connections as soft errors (retransmit opportunities), to prevent DoS.
Due to various path and link load-balancing methods, different packets can take a different path, and some might be queued differently along the path, or the path might have a different latency -- resulting in unpredictable ordering.
It is still TCP's job to produce a reliable stream from this.
And if Apache sent all the data, the client should get all the data, before they process the closing of the TCP stream....
Unless you have very high-speed TCP connections (sensibly more than 100Mbps/TCP connection) out-of-order packets should have no impact. At very high speeds, you may start seeing some performance decrease.
..... and then the security guys came with fancy ideas (badly) implemented in fancy firewalls .....
Did you check the http-server logs? Also you can run strace -p to see on system calls arguments and return values. Possible it shows you something interesting.
http://lwn.net/Articles/564825/
Implementing htb + fq_codel on your home router would help more.
http://snapon.lab.bufferbloat.net/~cero2/jimreisert/results.html
https://supportforums.cisco.com/document/48551/single-tcp-flow-performance-firewall-services-module-fwsm#TCP_Sequence_Number_Randomization_and_SACK
This way you can understand where in the path the the the ICMP unreachable came from
Agreed; a transparent proxy might have done this, after buffering the response on a slow connection it might have received close from server which might have lead to this ICMP error towards client.
I was thinking keepalive-timeout is applied to identify idle connection and triggered after completing the request but apache defines it as time after the last request received!! Is this a gap in our understanding or a bug?
we are talking about 2 issues here TCP connection close and TCP-re-order. Is there are relationship between them ?. As per one of the comments on TCP_Sequence_Number_Randomization_and_SACK, how does the end node behave when SACK is invalid ?
focusing on connection down issue, do not understand few things
1) If the problem is due to buffer bloat (atleast that is what it seem to indicate due to increase in http keepalive timer), the ICMP packet generated by IPtables seem to reach earlier than actual download packets. Does the ISP throttling based on amount of upload/download ?
2) The post has packet captures at one end, is there a packet captures from other end ?
1. ngnix chunked encoding + content length bug: in this case files were corrupted between backend and frontend servers, but frontend happily passed broken files to clients - fixed by disabling some nginx modules.
2. TCP offload on hypervisor-NIC received large segments and ACK'ed them on behalf of a VM, but VM's stack was out of buffers and never received this data - patially fixed with server-side shaping.