The Plexxi Challenge (or: Don’t Blame the Tools)
Plexxi has an incredibly creative data center fabric solution: they paired data center switching with CWDM optics, programmable ROADMs and controller-based traffic engineering to get something that looks almost like distributed switched version of FDDI (or Token Ring for the FCoTR fans). Not surprisingly, the tools we use to build traditional networks don’t work well with their architecture.
In a recent blog post Marten Terpstra hinted at shortcomings of Shortest Path First (SPF) approach used by every single modern routing algorithm. Let’s take a closer look at why Plexxi’s engineers couldn’t use SPF.
One Ring to Rule Them All
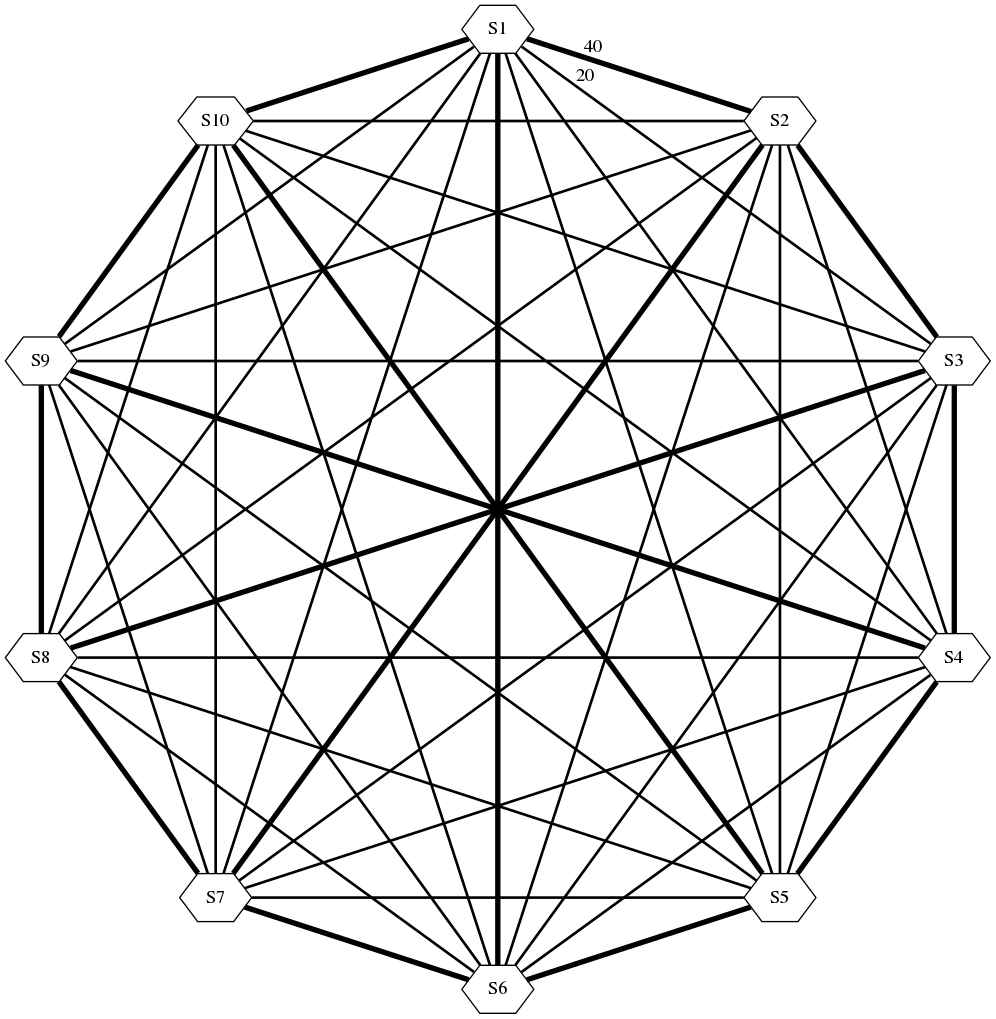
The cornerstone of Plexxi ring is the optical mesh that’s automatically built between the switches. Each switch can control 24 lambdas in the CWDM ring (8 lambdas pass through the switch) and uses them to establish connectivity with (not so very) adjacent switches:
- Four lambdas (40 Gbps) are used to connect to the adjacent (east and west) switch;
- Two lambdas (20 Gbps) are used to connect to four additional switches in both directions.

The CWDM lambdas established by Plexxi switches build a chordal ring. Here’s the topology you get in a 25-node network:

And here’s how a 10-node topology would look like:
The beauty of Plexxi ring is the ease of horizontal expansion: assuming you got the wiring right, all you need to do to add a new ToR switch to the fabric is to disconnect a cable between two switches and insert a new switch between them as shown in the next diagram. You could do it in a live network if the network survives a short-term drop in fabric bandwidth while the CWDM ring is reconfigured.
Full Mesh Sucks with SPF Routing
Now imagine you’re running a shortest path routing protocol over a chordal ring topology. Smaller chordal rings look exactly like a full mesh, and we know that a full mesh is the worst possible fabric topology. You need non-SPF routing to get a reasonable bandwidth utilization and more than 20 (or 40) GBps of bandwidth between a pair of nodes.
There are at least two well-known solutions to the non-SPF routing challenge:
- Central controllers (well known from SONET/SDH, Frame Relay and ATM days);
- Distributed traffic engineering (thoroughly hated by anyone who had to operate a large MPLS TE network close to its maximum capacity).
Plexxi decided to use a central controller, not to provision the virtual circuits (like we did in ATM days) but to program the UCMP (Unequal Cost Multipath) forwarding entries in their switches.
Does that mean that we should forget all we know about routing algorithms and SPF-based ECMP and rush into controller-based fabrics? Of course not. SPF and ECMP are just tools. They have well-known characteristics and well understood use cases (for example, they work great in leaf-and-spine fabrics). In other words, don’t blame the hammer if you decided to buy screws instead of nails.
More information
Dan Backman did a great job describing Plexxi ring architecture during the last Data Center Fabrics update session. If you’re even remotely interested in creative data center solutions you really should watch the recording of his presentation.
If you plan to stick to more traditional concepts, buy the recording of Clos Fabrics Explained webinar or watch free videos describing several leaf-and-spine deployment scenarios.
As always, thanks for the great write-up (and most excellent pictures!)
Just wanted to clarify one point that may be misunderstood by your readers. While it is true that SPF would have been a very poor choice for our topology, it is not the case that we built the physical topology and then were forced into choosing an appropriate routing algo design. In fact, when we started this project, the designers were given clear design goals from Dave Husak our founder. Those goals were - design a system that can compute deterministic topologies based on application affinity inputs, layered on a physical topology that can actually be manipulated dynamically. Everything else flowed from that. In fact, if we had chosen a leaf-spine physical architecture, we still would not have used SPF, which I will explain below.
Our issue with SPF/ECMP isn't that it isn't an appropriate tool for certain topologies and design philosophies - it certainly is, and I believe Marten stated as such in his own blog post. "Like ECMP and based on the fact that SPF algorithms have been in use in networks for probably 40 years, there is most certainly value in their ability to determine paths through a network. But also like ECMP, we have made them the center piece of connectivity, rather than one of many tools that can be used."
The reason Marten wrote the post you referenced is that we do feel that it is being stated that the most optimal design choice for every network is the most random, and we do not agree with that. We think that for certain data centers with high workload diversity and a propensity of east-west traffic, that we can do better (much better) than random distribution. I understand that "better" is vague and unqualified here, but what I mean is - at a lower overall cost (capex, power, space, operations), where more capacity is allocated to the edges of the network, and where network resources (such as low latency paths and capacity) can be directly applied to application intentions deterministically. Ultimately this all has to be measured in better application user experience at an equivalent or lower cost per bit.
We also believe that as the number of endpoints scales (physical hosts, virtual hosts, vSwitches) that an edge-to-edge oriented model where the edge patterns can be computationally fitted based on affinity knowledge can be designed to be much more efficient, scalable, and cost-effective than an aggregation model such as ECMP/Leaf-Spine. If the network is moving to the edge (hosts) then why duplicate costly and power hungry electrical silicon again in the agg/core? ECMP may be a great tool for Leaf-Spine, but Leaf-spine (or more generally aggregation oriented networks) may not be the best tool for networks that are trending to large number of host-to-host pairings. Instead if we can leverage edge-directed photonic switching, we can dramatically reduce the amount of costly electrical switching in the aggregation (and maybe someday even at the access layer) in networks. We'll discuss all of these topics and our fuller vision at NFD6 next week!
http://en.wikipedia.org/wiki/Blanu%C5%A1a_snarks
What you are calling "chordal" looks rather snark-like... but that's not why I'm posting....
I'm kind of curious as to whether or not these switches are fast enough to do fair queuing of any sort?
The Plexxi switches use commercial silicon (Broadcom, no secret) as their forwarding engines. It essentially supports Strict, Weighted Round Robin and Deficit Weighted Round Robin, the latter being the closest to fair queueing you can get given the speeds at which these switches need to operate (1.28Tbit/sec)...
If I had to design this system, using Openflow, I would rather balance traffic on a per-flow basis, using minimal or non-minimal routing depending on the current state of the network. If I understand it correctly, Openflow switches implement flow rules counters which would "easily" provide information about the current traffic load per flow. This would allow to better balance the traffic than using statistical hash buckets, which would generate unbalances depending on the specific fields used (MAC, IP, port) and the specific values of the endpoints.
Is there any document which details this implementation? I think that the Plexxi talk in the Datacenter Fabrics update did not go into the detail, and I didn't find the detailed information in their web. Thanks!!
as Ivan correctly states, the amount of explicit flow entries merchant silicon (and similarly for vendor ASIC) for 10GE ToR like form factor switches is limited to several 1000s per switch, unlikely enough to explicitly direct each and every flow in a DC environment.
In the Plexxi solution, we have no switch hierarchy but rather a mesh network between switches, which removes the need for the aggregation switches to have to support supersets of flow entries. In addition, not every flow in a Plexxi network is explicitly directed, a large portion of the traffic is directed using network wide topologies calculated by Plexxi Control and provided to the switches. And these topologies contain many weighted non equal cost paths used to populate regular forwarding tables (and thereby avoiding the flow tables limits).
We do not have anything written up explicitly about the internals of forwarding, I will put this on my list of whitepapers to complete.
If you plan to write about the internals of forwarding, it might also be very interesting to discuss the possible deadlock issues that might arise. I understand that in your system, when link-level flow control is configured (using PAUSE or PFC), circular dependencies could arise since you use multihop paths in a circulant topology, is that correct?.
AFAIK, deadlock management is a significant issue in HPC interconnection networks, where the traffic could even be part of a global coherence mechanism (see Cray XC30 'Cascade', for example) so any traffic blocking (and loss) is prevented by design. By contrast, it is generally ignored in Datacenter networks, typically for two reasons:
i) Ethernet networks have traditionally relied on (multi-)STP, which prevents forwarding loops by design, but this is no longer the case with TRILL, FabricPath, SPB, or your solution,
ii) Transport protocols above Ethernet (TCP or UDP) consider and tolerate packet loss, so switch buffers can be flushed (after a timeout without forwarding traffic) if the network blocks. However, with a converged fabric with storage & communications, where some loss in the transfer of a block in the storage network might imply a significant retransmission penalty, it seems that using a deadlock free network is much more important.
Then, my concern is: do you consider deadlock-freedom in your design? (for example, forbidding certain paths in the forwarding entries of the switch). Or is it just an academic concern which has never been seen in your real deployments? (Note: I am an academic :) )
Thanks in advance!