Multi-Vendor OpenFlow – Myth or Reality?
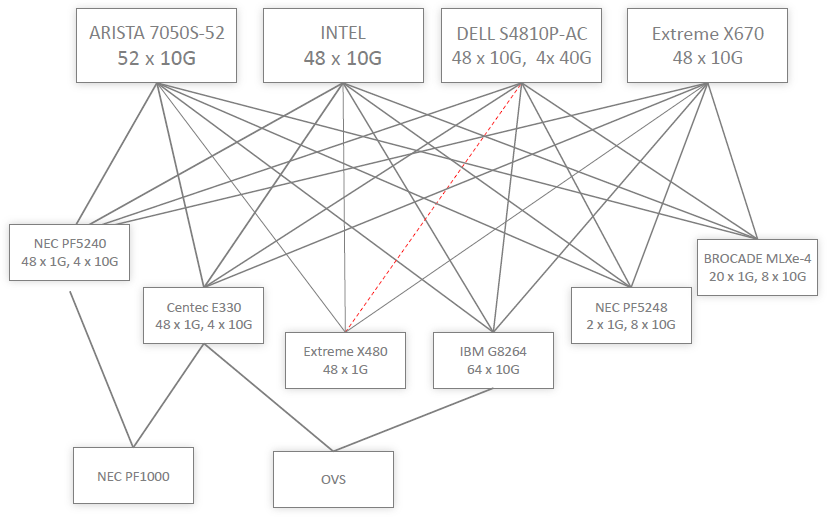
NEC demonstrated multi-vendor OpenFlow network @ Interop Las Vegas, linking physical switches from Arista, Brocade, Centec, Dell, Extreme, Intel and NEC, and virtual switches in Linux (OVS) and Hyper-V (PF1000) environments in a leaf-and-spine fabric controlled by ProgrammableFlow controller (watch the video of Samrat Ganguly demonstrating the network).
Does that mean we’ve entered the era of multi-vendor OpenFlow networking? Not so fast.
You see, building real-life networks with fast feedback loops and fast failure reroutes is hard. It took NEC years to get a stable well-performing implementation, and they had to implement numerous OpenFlow 1.0 extensions to get all the features they needed. For example, they circumvented the flow update rate challenges by implementing a very smart architecture effectively equivalent to the Edge+Core OpenFlow ideas.
In a NEC-only ProgrammableFlow network, the edge switches (be they PF5240 GE switches or PF1000 virtual switches in Hyper-V environment) do all the hard work, while the core switches do simple path forwarding. Rerouting around a core link failure is thus just a matter of path rerouting, not flow rerouting, reducing the number of entries that have to be rerouted by several orders of magnitude.
In a mixed-vendor environments, ProgrammableFlow controller obviously cannot use all the smarts of the PF5240 switches; it has to fall back to the least common denominator (vanilla OpenFlow 1.0) and install granular flows in every single switch along the path, significantly increasing the time it takes to install new flows after a core link failure.
Will the multi-vendor OpenFlow get any better? It might – OpenFlow 1.3 has enough functionality to implement the Edge+Core design, but of course there aren’t too many OpenFlow 1.3 products out there ... and even the products that have been announced might not have the features ProgrammableFlow controller needs to scale the OpenFlow fabric.
For the moment, the best advice I can give you is “If you want to have a working OpenFlow data center fabric, stick with NEC-only solution.”
More information
If you’re interested in a real-life OpenFlow fabric implementation, you simply must watch the ProgrammableFlow webinar recording – the ProgrammableFlow Basics section has a pretty good description of how path forwarding works.
Toss 2x10GBE, Mgmt, Monitor, Console and AUX.
Put it on a PCI 3.0 X16.
The cryptokey for the management server it phones home via the out-of-band mgmt network (configured via dhcp option code) is the license key.
Mgmt server configs the device via script which can be populated via an API. All interfaces are phy interfaces on the host os mapped into the VM. All MAC's are 802.1x authenticated. Intra-VM-Instance traffic goes over 16gbps PCI-E internal network through the card; if a vendor truely and really needs to move network traffic over memory between two VM's on the same machine, the hypervisor company is free to do as it wishes (virtual switch, and hey that traffic is separated from the rest of the network too!). All the hypervisor and host OS knows is the interface is a standard network interface (which keeps em' honest).
This card runs a firewall that can block, allow, (perform rudimentary but customizable) inspect, and\or tag all outbound traffic. If you want cutting edge network speed you can't offload routing onto the device without a lot of cost. So layer 2 switching with large cam tables to enable scaling, plus tagging to enable traffic flow customization for layer 3 routing (All the tag does is remap the destination MAC then place the packet on a trunk port, you can do that at 100gbps cheaply right?). With this setup you can even reliably transport SAN Traffic; to scale throughput to a server or SAN you add cards and use etherchannel. No "Overlay network" insanity.
Imagine seamlessly offering per-instance firewall, load balancer, IPS, and per-instance app services; all you do to turn it on is tag the traffic.
Hypervisor management software can seamlessly move VM's from A to B but their ability to do so is controlled by resource partitions you define on the cards (which really, when you get into the accounting end of things, is kind of a big deal).
You COULD install your Host OS then install a Control Stack (OS that controls the Hyper visor but is protected) network stack (VM that runs the above) and application instances (Hyper visors), and that's the way you've got to go to do true SDN. IMO there are security problems (Firewalls can be DOS'd by sending computationally expensive packets to them, and if you lock an IP after a certain number, then it becomes trivial to DOS via Spoofing) that this model solves.
That to me is the future of SDN. You put the router IN the computer on a separate card.