Equal-Cost Multipath in Brocade’s VCS Fabric
Understanding equal-cost multipathing in Brocade’s VCS Fabric is a bit tricky, not because it would be a complex topic, but because it’s a bit counter-intuitive (while still being perfectly logical once you understand it). Michael Schipp tried to explain how it works, Joel Knight went even deeper, and I’ll try to draw a parallel with the routed networks because most of us understand them better than the brave new fabric worlds.
Basics
Forget about TRILL, layer-2 forwarding and link aggregation (LAG, aka Port Channel or EtherChannel) for a moment. Imagine you’re working with routers running OSPF (or IS-IS) in a single area, and connect two of them with parallel 10GE links.
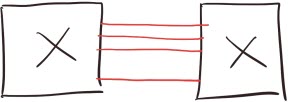
The bandwidth of each one of these links is 10 Gbps, and although there are four of them, the cost of each link reflects its bandwidth (10 Gbps). Assuming the OSPF reference bandwidth is set to 100 Gbps, the cost of each link would be 10.
There are four equal-cost paths between the switches, but the cost to get from one of them to the other is still 10, not 2 or 3. That’s how OSPF works ... and that’s how VCS fabric works as well.
With four equal-cost paths between two routers, the traffic will be split four ways, usually based on MAC or IP header information ... and here’s where the behavior of VCS traffic deviates from what we know from the router world.
Imagine three of the four links happen to be connected to the same port group (the ASIC which can do the proprietary perfect load balancing). These three links will receive 75% of the traffic, and that traffic will be load-balanced across all three of them. The remaining link will receive the rest of the traffic (25%).
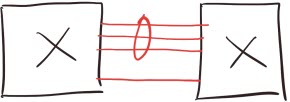
This behavior has some very interesting side effects: if the hashing algorithm used by the switch maps a TCP flow to the group of three links, a single TCP flow gets up to 30 Gbps of bandwidth (due to perfect load balancing), if the same flow gets mapped to the fourth link, it can never get more than 10 Gbps of bandwidth.
You need a server with multiple NICs configured in round-robin bonding mode to generate a TCP flow larger than 10Gbps.
Multi-hop Challenges
The behavior described in the previous paragraph is a bit counter-intuitive. Wouldn’t it be better to reflect the port groups in link costs? Actually, you’d get worse results in well-designed networks; in our previous scenario, the 30 Gbps LAG would have a cost of 3 and the 10 Gbps link would be ignored (because it would have higher cost).
Also, consider the following four switch network. Unless all link costs are equal, you’ll never utilize all links for traffic going between A and D.
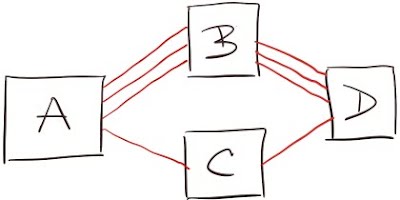
As always, there’s a counter-example. In the following network, A has four equal-cost paths to D, but 30 Gbps of bandwidth between A and B get reduced to 10 Gbps between B and D. The bandwidth reduction is not reflected in the routing protocol’s topology database: there are still four equal-cost paths from A to D. A will thus send 75% of the traffic to D toward B, overloading the B-D link.
This problem is not specific to VCS fabric or FSPF algorithm it’s using. OSPF or IS-IS would behave in exactly the same way.
There are only two ways you can solve this problem:
- Use traffic engineering to provision on-demand end-to-end bandwidth between ingress and egress switches;
- Use network design that is as symmetrical as possible (Clos fabrics being the best option).
In my opinion, a proper network design is always a better option, but of course some people tend to disagree.
More information
To learn more about Brocade’s VCS Fabric, watch the recording from the Tech Field Day event with Chip Copper. To see how it compares with other data center fabric solutions, watch the recording of my Data Center Fabric Architectures webinar, or attend a live session of the Clos Fabrics Explained webinar if you’re more interested in Clos architectures.
And don’t forget: you get access to both webinars (and numerous others) if you buy the yearly subscription.
I had 15 Gbps iperf flow between two VMs in the same hypervisor host, and the limit was the CPU/vSwitch, not the TCP performance.
You may have just blown my mind....Even if the server has a 10Gb uplink?
"per-packet: Performs load sharing in load-sharing link aggregation groups for each packet."