Does Optimal L3 Forwarding Matter in Data Centers?
Every data center network has a mixture of bridging (layer-2 or MAC-based forwarding, aka switching) and routing (layer-3 or IP-based forwarding); the exact mix, the size of L2 domains, and the position of L2/L3 boundary depend heavily on the workload ... and I would really like to understand what works for you in your data center, so please leave as much feedback as you can in the comments.
Background Information
Considering the L2/L3 boundary in a data center network, you can find two extremes:
Data centers that run a single scale-out application, be it big data calculations (Hadoop clusters, for example) or web portals. IP addressing and subnets usually don’t matter (unless you use weird tricks that rely on L2), and the L3 forwarding usually starts at the top-of-rack switch.
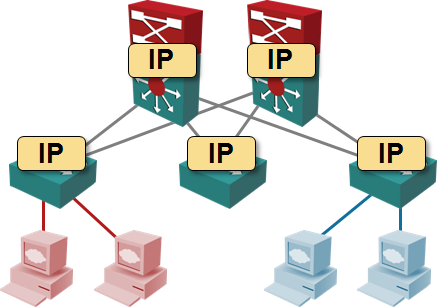
Cloud data centers that use MAC-over-IP encapsulations to implement virtual network segments are also in this category.
Fully virtualized data centers need large L2 domain to support VM mobility; VLANs extend across aggregation/core switches (or spine switches if you use Clos fabrics terminology).
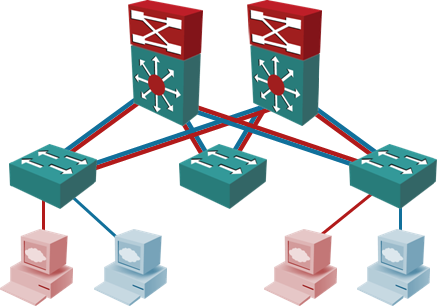
Data centers with large L2 domains usually use L3 forwarding only in the core switches; these switches have SVI (or RVI, depending on which vendor you’re talking with) VLAN interfaces, and IP addresses configured on VLANs. Most vendors have technologies that combine multi-chassis link aggregation with active-active forwarding (all members of an MLAG cluster share IP address and perform L3 forwarding between connected VLANs).
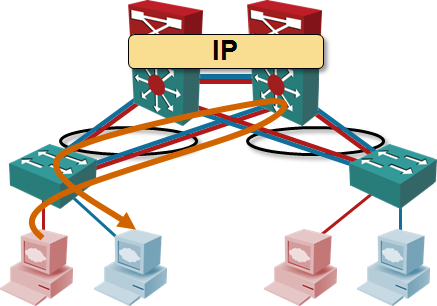
The Problem
L2 forwarding in ToR switches and L3 forwarding in the data center network core clearly results in suboptimal traffic flow. If you have servers (or VMs) in different VLANs connected to the same ToR switch, the traffic between them has to be hairpinned through the closest L3 switch. However, the question I’m struggling with is: “Does it really matter?”
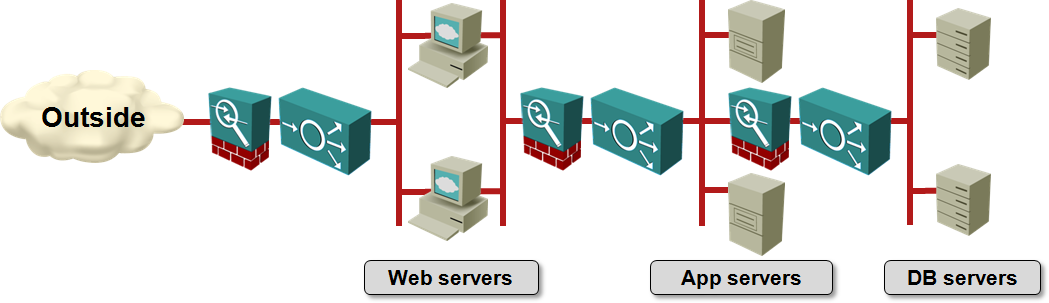
In most cases, you’d use VLANs in a virtualized environment to implement different security zones in an application stack, and deploy firewalls or load balancers between them. If you do all the L3 forwarding with load balancers or firewalls, you don’t need L3 switches, and thus the problem of suboptimal L3 forwarding becomes moot.
Feedback highly appreciated!
As I wrote in the introductory paragraph, I would really like to understand what you’re doing (particularly in environments using VMs with large VLANs). Please share as much as you can in the comments, including:
- Do you use L3 forwarding on the data center switches;
- Where do you deploy L3 switching (ToR/leaf, aggregation, core/spine);
- Why do you use L3 forwarding together with (or instead of) load balancers and/or firewalls;
- Do you see suboptimal L3 forwarding as a serious problem?
Thank you!
For firewall: iptables on every host, acls and monitoring.
You should go with ToR from the beginning, if you can afford it.
Nice post Ivan.
DataCenter:
9 x ToR L2 stackable-switch, with 2x10Gbps aggregation to the 2 Core Switches and each ToR has 2 units with 48x1Gbps ports;
2 x L3 Core DataCenter Switchs, with 12 VLANs, and L3 between "Core DataCenter Switchs" and "Core Users Switchs"
On Core Users Switchs, we have 95 VLANs.
Don't think in L3 on ToR, yet.
L3 TOR will typically provide much better flow hashing than glbp/hsrp/vrrp. You get per flow hashing and not per host hashing. It is also easier to go more than 2 wide above your TORs with L3 vs L2. Troubleshooting L3 is much saner than trying to troubleshoot evil protocols like virtual port-channels.
Optimal forwarding is nice. I see L3 as orthogonal to firewalls and load balancers, at least at scale.
If you are talking about a "datacenter" with a few dozen racks where all the config is hand managed, it probably doesn't matter. If you're network is small enough that a single engineer can hand manage it, stunt networking with vPC and vlans everywhere won't be an issue. Until you try grow it out by an order of magnitude. Then you'll be screwed.
IMHO
Strictly M1 F1 card speaking - Nexus 7000 switches require an M1 card to route traffic. Each M1 card can route 80Gb throughput. If i have one M1 card and 9 F1 cards and all servers are on their own subnet (hello VSheild Edge or VSG) then they need to get routed. Routing over-subscription can reach 1 to 36.
M2/F2 series run into same issues with lower OSR.
If you want your 7K pair to never be oversubscribed then you need to plan around routing.
That's why I try to design L2 domains that will rarely route to other L2 domains in a data center if i can prevent it.
If you can connect all your racks to a single pair of routers, it probably isn't a big deal.
IMHO
If you can connect all your racks to a single pair of routers, it probably isn't a big deal.
IMHO
2 DCs are paired by DWDM and short distances to be able to accommodate capacities in excess of 100 Gbps and low latencies for whatever FC or Ethernet based replications people want to do.
At each DC we have a lan core of 2xN7Ks, end of row of 2xN5Ks for every row, and the N2Ks FECs for the top of rack which connect to blade/chassis based switches. So, many port channels and many trunks everywhere.
Naturally, the biggest point of disagreement between the server/application teams and the network team was the border between L2 and L3. Ultimately, we brought L2 back to the lan core. To the other DC, rest of the Wan, load balancing infrastructure, or services on the other side of firewalls, we route at L3.
Suboptimal forwarding performance, within the L2/L3 switched lan environment, is less a concern to us, than the performance limitations we have when traversing our firewalls, IPSs, or Wan. Even when packets or frames need to come back to the core, we are probably looking microseconds of additional delay versus milliseconds of delay.
Another important consideration for us, is routing into and out of the pair of data centers requiring symmetry for wan optimization and security. This forced a certain level of suboptimal routing into the design.
Another reader mentioned simplicity of design. In my opinion, this is even more critical than sub-optimal routing to the performance of a data center within the data center. If only high level engineers can troubleshoot and resolve issues, due to the complexities of the data center, then the time to resolution increases substantially as there are generally fewer of these engineers around.
The only caveat is that the uplinks and hardware has the capacity to be able to forward the traffic.
However, routing protocols require actual configuration, some knowledge, and might take a few seconds to converge.
Given the typical tools of VLAN and VRF, many datacenters would find that VRF support is lacking and/or burdensome to support in access and aggregation tiers. So VLANs make more sense, bridging at the access/agg with routing happening in the "core" or WAN edge. Of course, this also gives a larger broadcast domain and might facilitate mobility, plug and play behaviors, etc.
As to traffic patterns: If we're using VRFs for the routing edge, then maybe it doesn't matter - if the VRFs are supporting different VPNs then inter-VLAN traffic isn't likely anyway. On the other hand, if each VRF is routing (e.g. locally) between multiple VLANs then you get a traffic trombone. It's not very efficient of course, in terms of capacity etc, but even a "traffic trombone" is possibly a good tradeoff in terms of centralizing the VRF capability and configuration. And as you point out, we may have this traffic pattern anyway because of e.g. the location of the security edge (firewall) or load-balancer.
In other environments, VRF support may not be necessary for L3, e.g. because we're attaching everything to "the Internet" or some other common network. In that case, it might make more sense to route in the access and/or aggregation layer. Plain L3 routing is more likely to be supported in various equipment, and it's somewhat easier to manage.
And we can always run both L2 and L3 throughout the datacenter - L3 on the access node for routing to the Internet and L2 for carrying traffic to centralized VRF PEs, or something like that. You can probably imagine other ways to combine these; the point is that each design will be judged based on the purpose / goal of the datacenter, so there's probably no "one size fits all" answer here.
Of course, all of this might become moot with overlays and SDN architectures. At some point, the underlying network can be all-L3 and the "service" can be a mix of L2 and L3. Depending on how much control is built into the control plane, we might be able to do interesting policy and non-traditional forwarding... But that's a topic for another day. :)
13 years later, some things haven't changed much
I recently joined a new company, and I'm told that while designs started out with L3 at ToRs, things have standardized on L2-only ToRs with routing at the core switches (VRRP pair per VLAN). The reason is because of what invariably happened: Applications would grow out of their initial /24 subnet, and the team would have to stretch the original /24 VLAN - which had now gotten too small - to a new pair of Tor switches.
It's not about "optimal L3 forwarding" - it's about configurations that don't need to change