Rant: Multi-Vendor EVPN Fabrics
Daniel Dib tweeted about an old comment of mine a few days ago, adding1:
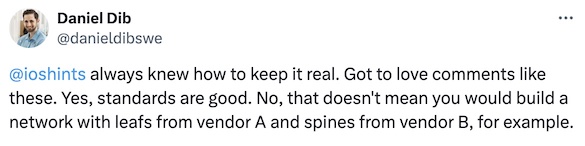
Not surprisingly, that was bound to upset a few people, and Roman Dodin quickly pointed out the EVPN interoperability tests:
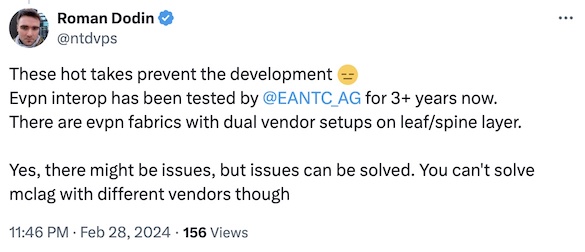
Roman is absolutely correct. Vendors have been running EVPN interoperability tests for years, and recent results showed surprising levels of interoperability. Considering Daniel’s original scenario, you could also build a fabric where the spine switches run just an IGP, so you’d get almost guaranteed interoperability, but I’m digressing.
Looking back, vendors had been running OSPF or SIP interoperability tests for years2, and still, it took a long time for the technology to stabilize enough for people who love not being on a frantic conference call with a network-down situation to start building multi-vendor solutions with those technologies3.
You see, there’s a fundamental difference in perspective if you consider multi-vendor interoperability as a runner-up box builder or a network builder using other people’s boxes. I understand that vendors get upset when people like Daniel or myself say, “I see no reason why I would make my life harder building a multi-vendor EVPN data center fabric,” however, it’s hard enough being the QA department for a single vendor4, let alone being an interoperability test bed and QA department for multiple vendors. It took some vendors years to get the VXLAN/EVPN gear they were selling to the point where it could be safely used in production networks. Why should we believe they’re doing a better job with multi-vendor interoperability?
A recent LinkedIn comment is a perfect illustration of what I’m talking about:
One thing that is really hard to simulate in a lab, which gives me serious heartburn with VXLAN implementation, is what happens when you get a bad- or stale state in the table. So far, I’ve been unable to find a better solution than clear bgp all, which is somewhat acceptable when services are partition tolerant and a complete nightmare when they are not.
Vendors have been “shipping” EVPN/VXLAN for years, and we’re still dealing with BGP tables or forwarding tables are messed up scenarios. Do I need to say more?
Now for a slightly more nuanced perspective. Roman also argued that there’s a difference between EVPN services and MC-LAG and he’s absolutely correct.
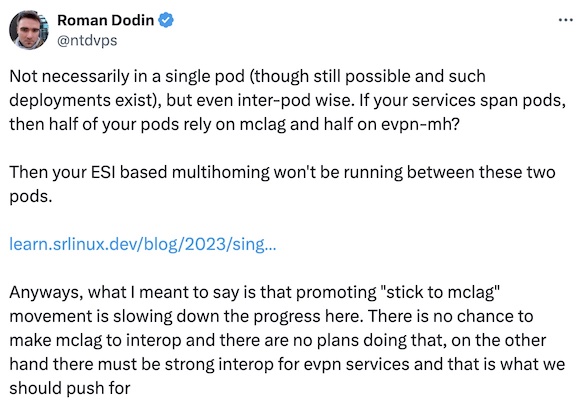
However, due to the influence of PowerPoint creators and EVPN gospel spreaders on people who prefer believing vendors instead of doing their own research, every time someone mentions MC-LAG, a LinkedIn Engagement Farmer Thought Leader inevitably writes a comment saying “you should use EVPN ESI, that’s a standard” without realizing it takes more than the engine (EVPN ESI) to build a car (a solution in which two boxes pretend to be one). Some other parts of MC-LAG solutions are standardized (ICCP), while others are not. Yet you need all of those building blocks if you want to build a link aggregation group with member links connected to different devices. Stick to MC-LAG movement5 is not slowing progress but pointing out the inevitable reality6 to people who think a sprinkle of unicorn dust (EVPN ESI) solves a complex technology challenge.
I don’t care if some vendors believe they should implement MC-LAG with EVPN ESI technology while others think they should use anycast IP. It’s the vendors’ job to ensure the two types of solutions are interoperable in large fabrics, but that still wouldn’t persuade me to build a data center layer-2 domain7 with boxes from two vendors. Carrier Ethernet networks are a different story8, but even there, one should keep all endpoints of a link aggregation group connected to the same type of boxes for consistency reasons.
Last but not least, this saga proves vendors learned nothing from the OSPF debacle of the mid-1990s:
- The development of the EVPN RFCs was mostly vendor-driven (because nobody else would pay top-notch engineers to
wastededicate their time to arguing about the number of angels dancing on virtual pins). - As usual, most parts of the EVPN standards were made optional because nobody in their right mind would agree to have something they haven’t implemented yet be MANDATORY.
- Vendors decided to implement different subsets of the EVPN standards and used standards in different creative ways, creating the whole interoperability mess in the first place.
- Don’t get me started on the crazy ideas of running IBGP over EBGP because (A) EVPN was designed to be used with IBGP and IGP, and (B) EBGP-as-IGP craze took over in the meantime.
- Rushing to market with broken implementations didn’t help build the end-user confidence either.
So, if you’re working for a vendor, don’t complain when old-timers like Daniel and myself say, “I love quiet evenings and would try to avoid multi-vendor fabrics as much as possible.” I know most of you weren’t there when this particular complexity sausage was being made. Still, your company might have helped create that sentiment in the first place (probably not starting with EVPN), and unfortunately, you have to share the consequences. However, I agree that (A) EVPN is probably the way to go if one wants to build layer-2+3 VPNs, and (B) interoperability matters, so please keep up the good fight!
-
As I stopped believing in the long-term viability of the site formerly known as Twitter, I’m taking screenshots of what people were saying to have them preserved in a place where I can control their durability ;) ↩︎
-
How do you think The Interop started? It evolved from the 1986 TCP/IP Vendors Workshop. ↩︎
-
Remember the good old days when OSPF stopped working after a few weeks due to whatever counter overflow? I tried to find something describing that behavior (and failed) and uncovered tons of recent reports of weird OSPF behavior. Do I have to point out that OSPF is almost 30 years old and relatively trivial compared to EVPN? ↩︎
-
Let’s be realistic and admit it’s impossible to test every single deployment scenario of a complex distributed system. It’s also impossible to predict the crazy ways in which MacGyvers of the networking world will use your boxes. On the other hand, it’s inexcusable to ship a virtual appliance with a broken DHCP client and then take over three months to release a fixed image. Nonetheless, I want to avoid being unpaid vendors’ QA department as much as possible. ↩︎
-
Of which I’m not a member. I’ve been recommending to get as far away from MC-LAG as possible at the network edge or in the fabric core for a decade. ↩︎
-
And I completely understand that some people prefer not to discuss the state of their wardrobe. ↩︎
-
… or VLANs stretching across continents or reaching into a public cloud. ↩︎
-
Data center pods are often built and deployed as a single project, whereas Carrier Ethernet networks usually grow organically over decades. ↩︎
Rant is mentioned in the title, so let's fuel it a bit ;)
"crazy ideas of running IBGP over EBGP" allow you to achieve exactly what was mentioned in the first question - EVPN-VXLAN fabric with spines doing only plain IPv4 forwarding with eBGP signaling.
I doubt you can find more interoperable protocol than eBGP AFI/SAFI 1/1. Definitely better than OSPF in this aspect. Try to change my mind ;)
I personally saw networks built using one vendor for TORs and 2 different vendors for spines, and this design makes a lot of sense for many reasons.
> "crazy ideas of running IBGP over EBGP" allow you to achieve exactly what was mentioned in the first question - EVPN-VXLAN fabric with spines doing only plain IPv4 forwarding with eBGP signaling.
As long as you don't run BGP RR on the spines ;) For whatever crazy reason, most vendors promoting this design forget about this tiny little detail ;))
> I doubt you can find more interoperable protocol than eBGP AFI/SAFI 1/1. Definitely better than OSPF in this aspect. Try to change my mind ;)
Trying to change ingrained beliefs is futile. Let's just say that most of the Internet runs on OSPF/IS-IS + IBGP/EBGP, and it mostly works.
> I personally saw networks built using one vendor for TORs and 2 different vendors for spines, and this design makes a lot of sense for many reasons.
... at scale.
Average company is blessed beyond their wildest dreams to find an engineer who understands what a BPDU is and that bridging loops are bad. L2oL3, MP-BGP AFIs, ESIs, VTEPs....not supportable by 99% of the wild. All just pushing the needle on sales. 4k VLAN limit isn't a valid argument in the 99% either.
Thanks for your rant, very interesting! Could you please explain the mid-1990's OSPF debacle, for those of us (just slightly) younger?
OSPF was brand new at that time and (according to some rumors) wasn't implemented optimally on some platforms. The fact that it was overspecified and that Cisco kept pushing its own routing algorithm (IGRP, later EIGRP) didn't help either.
Anyway, getting OSPF to work reliably across three major vendors at that time was a bit of a challenge, not to mention four versions of OSPFv2 (1247, 1583, 2178, 2328) and stuff that kept appearing, like NSSA and demand circuits.
FWIW, Nexus OS has (had?) the "rfc1583compatibility" nerd knob, and RFC 1583 was published in March 1994 (= exactly 30 years ago).
All good and valid here except OSPF is not trivial - those who have implemented it do know.
> All good and valid here except OSPF is not trivial - those who have implemented it do know.
Is bloatware we made out of the three-napkin protocol any simpler? I found a simple scenario a few days ago where different implementations disagree on what the result should be almost 30 years after the BGP4 specs were written. Details coming in a blog post (where else ;)