Category: networking fundamentals
Graceful Restart and Routing Protocol Convergence
I’m always amazed when I encounter networking engineers who want to have a fast-converging network using Non-Stop Forwarding (which implies Graceful Restart). It’s even worse than asking for smooth-running heptagonal wheels.
As we discussed in the Fast Failover series, any decent router uses a variety of mechanisms to detect adjacent device failure:
- Physical link failure;
- Routing protocol timeouts;
- Next-hop liveliness checks (BFD, CFM…)
Video: Theoretical View of Network Addressing
After explaining the basics of (network) names, addresses and routes, I wasted a few minutes of everyone’s time discussing the theoretical aspects of layered addressing, and then got back to practical issues like address scopes, namespaces, and address provisioning.
The video ends with a simple (and unappreciated) truth: if you have a point-to-point link between two nodes you don’t need data-link-layer addresses. The consequences of that fact are left as an exercise for the viewer (or you can wait till the next video ;)
Graceful Restart and Other Control Plane Protocols
In the Graceful Restart 101 blog post, I promised to discuss the ugly parts of this concept in a follow-up post. It turns out we’ll need more than one; today, we’ll focus on other control plane protocols in an access network scenario.
Imagine an access router with multiple uplinks serving a bunch of non-redundantly-connected customers:
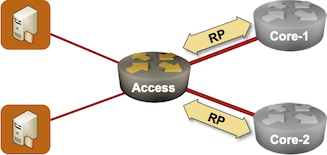
Non-redundant access network
Graceful Restart (GR) 101
In the Non-Stop Forwarding (NSF) article, I mentioned that the routers adjacent to the device using NSF have to play along to make the idea work. That capability is called Graceful Restart. Today we’ll explore its intricate details, be diplomatic, and leave the shortcomings and tradeoffs for the next blog post.
The Problem
Imagine an access (provider edge) router providing connectivity services to its clients and running a routing protocol with one or more upstream devices.
Stateful Switchover (SSO) 101
Stateful Switchover (SSO) is another seemingly awesome technology that can help you implement high availability when facing a broken non-redundant network design. Here’s how it’s supposed to work:
- A network device runs two copies of the control plane (primary and backup);
- Primary control plane continuously synchronizes its state with the backup control plane;
- When the primary control plane crashes, the backup control plane already has all the required state and is ready to take over in moments.
Delighted? You might be disappointed once you start digging into the details.
Lessons Learned: Fundamentals Haven't Changed
Here’s another bitter pill to swallow if you desperately want to believe in the magic powers of unicorn dust: laws of physics and networking fundamentals haven’t changed (see also: RFC 1925 Rule 11).
Whenever someone is promising a miracle solution, it’s probably due to them working in marketing or having no clue what they’re talking about (or both)… or it might be another case of adding another layer of abstraction and pretending the problems disappeared because you can’t see them anymore.
Non-Stop Forwarding (NSF) 101
Non-Stop Forwarding (NSF) is one of those ideas that look great in a slide deck and marketing collaterals, but might turn into a giant can of worms once you try to implement them properly (see also: stackable switches or VMware Fault Tolerance).
Video: Introduction to Network Addressing
A friend of mine pointed out this quote by John Shoch when I started preparing the Network Stack Addressing slide deck for my How Networks Really Work webinar:
The name of a resource indicates what we seek, an address indicates where it is, and a route tells us how to get there.
You might wonder when that document was written… it’s from January 1978. They got it absolutely right 42 years ago, and we completely messed it up in the meantime with the crazy ideas of making IP addresses resource identifiers.
Video: Typical Large-Scale Bridging Use Cases
In the previous video in the Switching, Routing and Bridging section of How Networks Really Work webinar we compared transparent bridging with IP routing. Not surprisingly (given my well-known bias toward stable solutions) I recommended using IP routing as much as possible, but there are still people out there pushing large-scale transparent bridging solutions.
In today’s video we’ll look at some of the supposed use cases and stable solutions you could use instead of stretching a virtual thick yellow cable halfway across a continent.
Video: Comparing Routing and Bridging
After covering the basics of transparent Ethernet bridging and IP routing, we’re finally ready to compare the two. Enjoy the ride ;)
Lessons Learned: Technology Still Matters
In June 2020, a friend asked me to do a short presentation on lessons learned during my 35 years as a networking engineer. It went reasonably well, so I decided to turn it into a webinar, starting with regardless of what the disruptive marketers tell you, technology still matters.
… updated on Monday, July 12, 2021 18:00 UTC
Unnumbered Ethernet Interfaces, DHCP Edition
Last week we explored the basics of unnumbered IPv4 Ethernet interfaces, and how you could use them to save IPv4 address space in routed access networks. I also mentioned that you could simplify the head-end router configuration if you’re using DHCP instead of per-host static routes.
Obviously you’d need a smart DHCP server/relay implementation to make this work. Simplistic local DHCP server would allocate an IP address to a client requesting one, send a response and move on. Likewise, a DHCP relay would forward a DHCP request to a remote DHCP server (adding enough information to allow the DHCP server to select the desired DHCP pool) and forward its response to the client.
Real-Life Network-as-a-Graph Examples
After reading the Everything Is a Graph blog post, Vadim Semenov sent me a long list of real-life examples (slightly edited):
I work in a big enterprise and in order to understand a real packet path across multiple offices via routers and firewalls (when mtr or traceroute don’t work – they do not show firewalls), I made OSPF network visualization based on LSDB output. The idea is quite simple – save information about LSA1 and LSA2 (LSA5 optionally) and that will be enough in order to build a graph (use show ip ospf database router/network on Cisco devices).
Routing Protocols: Use the Best Tool for the Job
When I wrote about my sample OSPF+BGP hands-on lab on LinkedIn, someone couldn’t resist asking:
I’m still wondering why people use two routing protocols and do not have clean redistribution points or tunnels.
Ignoring for the moment the fact that he missed the point of the blog post (completely), the idea of “using tunnels or redistribution points instead of two routing protocols” hints at the potential applicability of RFC 1925 rule 4.
Unnumbered Ethernet Interfaces
Imagine an Internet Service Provider offering Ethernet-based Internet access (aka everyone using fiber access, excluding people believing in Russian dolls). If they know how to spell security, they might be nervous about connecting numerous customers to the same multi-access network, but it seems they have only two ways to solve this challenge:
- Use private VLANs with proxy ARP on the head-end router, forcing the customer-to-customer traffic to pass through layer-3 forwarding on the head-end router.
- Use a separate routed interface with each customer, wasting three-quarters of their available IPv4 address space.
Is there a third option? Can’t we pretend Ethernet works in almost the same way as dialup and use unnumbered IPv4 interfaces?